Introduction à Git
Jessica Malko
Décembre 2023
Plan de la présentation
- 1. Introduction
- 2. GIT
- 3. Univers Git
- 4. Atelier
- Partie 1 : Utilisation de Git au travers du Terminal
- Étape 7:
- Partie 2 : Utilisation de GitHub Desktop
- Astuces :
- Conclusion
- Merci pour votre attention!
- :)
1. Introduction
Git c’est un système de contrôle des versions (VCS) applicable au développement de logiciels (comme l’écriture de code R pour l’analyse de vos données). Les logiciels sont un ensemble d’instructions ou de programmes qui disent à l’ordinateur ce qu’il doit faire. Git est lui-même un logiciel.
Il existe différentes méthodologies pour développer des logiciels.
Ces méthodologies permettent de mettre en place un processus structurant lorsqu’on travaille sur un projet.
Il s’agit d’un mélange de pragmatisme et de philosophie du design.
L’objectif d’une méthode est de fournir une approche systémique au développement de logiciels pour encadrer et harmoniser le travail d’équipe. Il n’existe pas de méthode meilleure que les autres. Chaque méthode offre une stratégie différente que nous pouvons classer dans l’une des trois catégories:
- Waterfall
- Itératif
- Continu
Avant de poursuivre dans le vif du sujet, nous allons en discuter brièvement pour vos donner des idées de quelle méthode pouvant inspirer et structurer votre propre workflow.
Méthodologies
-
Catégorie WATERFALL
Comme exemple de la catégorie Waterfall, prenons la méthode du même nom. La méthode Waterfall est une méthode linéaire qui consiste en une série d’étapes séquentielles dite en cascade. Cette méthode est idéale pour des projets simples dont les résultats sont prévisibles.
Les avantages: c’est une méthode facile à comprendre (linéaire), tout est déterminé avant que le développement ne débute (livrables, spécifications, etc.).
Les inconvénients: Le risque d’échec est accru puisqu’il est très difficile de tout prévoir d’avance, il n’y a aucun test en cours de route pour déceler les bugs, il n’y a aucun retour ou feedback du client en cours de route et cette méthode ne prévoie aucune place à l’adaptation ce qui en fait une méthode mal adaptée pour les projets complexes. -
Catégorie ITÉRATIF
Comme exemple de cette catégorie, nous pouvons penser à la méthode Agile et Rapid. La catégorie Itérative permet la révision constante en lot. L’équipe développe le logiciel par itération contenant de petits incréments de la nouvelle fonctionnalité. Elle nécessite une approbation continue du client à chaque itération ce qui en fait une méthode idéale pour des projets dont les besoins évoluent rapidement.
Les avantages: peu de bugs puisque les améliorations sont fréquentes et par incréments, cette méthode permet d’effectuer des changements rapides pour répondre aux besoins qui évoluent dans le temps avec peu d’impacts sur l’échéancier.
Les inconvénients: c’est une méthode énergivore pour l’équipe vu le temps nécessaire à l’implication constante du client tout au long du processus, c’est une approche non-structurée qui requiert une équipe composée de développeurs d’expérience capables de travail indépendant. -
Catégorie CONTINUE
Comme exemple de la catégorie en Continue, nous pouvons penser à la méthode LEAN ou DevOps. Il s’agit de méthodes qui permettent une mise à jour continue suivant différents principes.
La méthode LEAN aurait été inspiré par Toyota Production Systems et se concentre à minimiser le gaspillage et augmenter la productivité en suivant 5 principes : Define value, Map value stream, create flow, establish pull et pursuit perfection. Cette méthode encourage l’équipe à garder l’esprit ouvert et de considérer tous les facteurs avant de finaliser une décision. Les développeurs identifient des goulots potentiels au processus en vue d’établir un système efficient. Cette méthode met l’emphase sur le respect humain, notamment via la communication comme clef pour l’amélioration de la collaboration et l’efficience de l’équipe.
Les avantages: réduit le gaspillage de codes redondants et de tâches répétitives, augmentation de la motivation des membres de l’équipe qui détient une part de responsabilité dans la prise de décision. Les inconvénients: requiert une équipe hautement qualifiée.
DevOps
DevOps est une philosophie parue en 2007-2008 qui est considérée une méthode de catégorie Continue par certain. DevOps élimine le travail en silo des équipes de DÉVeloppement et des OPÉrations (d’où il tire son nom). Son objectif est de se rapprocher du client afin d’éliminer les assomptions de ce que le consommateur veut. C’est une approche visant à ce que l’équipe ait “une compréhension holistique du produit, de la création jusqu’à son implémentation.” (www.synopsys.com).
Pour ce faire, DevOps combine en une seule équipe multidisciplinaire les 3 secteurs : le développement de logiciels, l’assurance qualité par la mise à l’essai du logiciel et le support technique informatique directement en contact avec le client.
Les avantages: réduction du taux d’échec et du temps de déploiement, l’amélioration de : la satisfaction de la clientèle, la qualité du produit et la productivité de l’équipe.
Les inconvénients: certains clients ne veulent pas de mises à jours fréquents (on peut penser au instances gouvernementales qui doivent faire approuver chaque version), certaines industries ont une régulation stricte pour les nouvelles versions, certaines étapes du contrôle qualité requiert une interaction humaine pouvant ralentir le cheminement.
Maintenant qu’on sait comment travailler, il faut se munir de bons outils pour y parvenir
Version Control System
L’outil indispensable pour la programmation et l’écriture de code est le Système de Contrôle de Versions (VCS étant l’abréviation anglophone utilisée sur le web). Le premier VCS existe depuis le milieu des années 1970.
VCS c’est “[…] the practice of tracking and managing changes to software code” (www.Atlassian.com) ou la “pratique de suivre et de gérer les changements au code de logiciels” au fil du temps (traduction libre).
Le VCS n’est pas un backup ni une sauvegarde. C’est plutôt un screenshot de notre projet à un temps donné.
Le VCS est l’outil en charge de gérer ces screenshots. Il permet à plusieurs personnes de travailler sur le même projet en même temps sans perdre le fil de qui fait quoi et quand.
En somme:
- il aide l’équipe à gérer et suivre les changements du code au fil du temps;
- il s’adapte à différentes méthodes et différents environnement de travail;
- il permet à l’équipe de travailler plus efficacement (faster and smarter);
- il garde une trace de chaque modification du code dans une base de donnée et
- il protège le code de catastrophes accidentelles ou volontaires (logiciel malveillant, pirate, fraudeur, etc.).
2. GIT
Git est un logiciel VCS qui s’adresse autant aux débutant qu’à l’utilisateur avancé, au travail individuel et collaboratif.
Il est excessivement rapide, capable de gérer toute taille de projet. Il est gratuit, open source, et a une empreinte essentiellement invisible* sur votre ordinateur.
* invisible dans le sens qu’il n’est pas muni d’un Graphic User Interface (GUI) ce qui peut le rendre intimidant aux personnes non initiées à utiliser les lignes de commandes directement dans le Terminal (Mac) ou cmd.exe (Windows). Nous verrons un exemple de programmation dans le Terminal dans la première partie de l’atelier à la section 4.
À propos
Regardons les différents aspects de Git. (L’ensemble de l’information de cette section provient du site web git-scm.com)
Branching and merging
Git permet la commutation (remplacement, échange) sans friction.
On créé une nouvelle branche à partir de la branche principale pour essayer quelque-chose (une nouvelle idée, un code risqué) en pouvant retourner au point de départ à n’importe quel moment.
Le flux de travail (Workflow) est basé sur les branches qui permettent de travailler le code en sous-section sans affecter le code principal sur la branche principale.
On peut facilement faire des expériences jetables qu’on peut garder pour soi sans les partager aux autres.
Distributed
Git est un système distribué (contrairement à un système centralisé)
Ceci implique que l’on prend l’ensemble du projet localisé sur le serveur (blessed REPO) et qu’on en fait une copie complète localement sur notre ordinateur (REPO local).
Avec un système centralisé, nous n’avons pas de copie du REPO sur notre ordinateur. Seul le fichier contenant le travail actif est hébergé localement ce qui ralentit non seulement le travail de l’individu, mais de l’équipe également.
Donc, le système distribué signifie que chaque personne a un clone local. Ceci implique qu’il y a des backups multiples du REPO ce qui protège le progrès de tout avarie. Cela permet également une plus grande flexibilité dans le style du workflow ou flux de travail pouvant être utilisé : style de subversion, style de gestionnaire d’intégration ou style dictateur et lieutenant.
(une synthèse visuelle est disponible sur le site git-scm.com)
- DÉFINITIONS
* REPO : c’est le dossier du projet qui contient toutes ses parties. Le dossier du projet devient un REPO dès lorsqu’on le confie à un VCS.
* blessed REPO : un REPO hébergé sur un serveur (dans les nuages). L’équipe s’en sert comme copie de référence.
* REPO local : le REPO au niveau local (sur le disque de notre ordinateur). Ça peut être soit une copie d’un blessed REPO hébergé sur un serveur ou un REPO d’origine local.
Small and fast
Git est excessivement rapide à comparer à un système centralisé dans toutes les opérations sauf le clonage initial d’un projet. Quand on y réfléchi, c’est tout à fait normal: lors du clonage initial, nous copions le REPO complet qui contient toute l’historique de tous les changements ayant eu lieu entre chaque COMMIT.
Selon un test de vitesse benchmark, Git serait 325 fois plus rapide qu’un système centralisé pour faire un COMMIT de tous les fichiers comparativement au clonage initial d’un REPO hébergé vers notre ordinateur pour lequel il serait 7.5 fois plus lent. Ceci dit, Git est 4 fois plus rapide pour le commit des fichiers une fois le clonage initial effectué.
- DÉFINITIONS
* COMMIT : c’est l’action de faire un screenshot de notre travail et de le confier au VCS.
Data assurance
Le VCS consigne chaque commit à l’aide d’un identifiant unique. Le commit contient les fichiers, la date et un message qui décrit les changements consignés. Il est impossible* d’en modifier le contenu ou de le falsifier. Git permet cependant d’effectuer facilement un addenda advenant l’oubli d’un fichier ou l’omission d’un petit détail.
* À dire vrai, il est possible d’aller modifier l’information contenu dans les commit mais cela est rendu très difficile et ardu (cela va à l’encontre de l’objectif du VCS). Donc pour toute fin pratique, il vaut mieux de se dire qu’il en est impossible.
Staging area
La scène de montage (traduction libre de staging area) est une fonctionnalité unique à Git. Elle permet à l’utilisateur d’ajouter les éléments souhaités un à un (ou tous ensemble) dans un emplacement où les réviser avant de les commettre. L’ajout des éléments à la scène de montage à partir de notre répertoire de travail se fait à l’aide de la commande ‘git add’ suivi du nom des fichiers souhaités. Lorsque nous sommes satisfaits des fichiers dans la scène de montage, nous pouvons ensuite commettre notre travail dans le REPO par la commande ‘git commit -m’. Cette commande nous permet d’inscrire notre message contenant les détails du travail pouvant aider, nous ou nos collègues, à comprendre l’essentiel des changements dans le temps.
- Pour résumer
* Git effectue le suivi du contenu et non du nom des fichiers (version 1, version 2, version finale, version finale vrai).
* Git est ouvert; il permet aux gens d’offrir une contribution qui, suite à une analyse, peut être intégrée au blessed REPO.
* Git est un système distribué; tous les utilisateurs ont une copie intégrale du REPO hébergé.
* Git permet de garder un registre des changements (deltas) en fonction de : qui, quand comment et pourquoi.
* Git s’adapte aux conditions de travail; hors ligne sur un vol d’avion, lors d’une panne de courant, en télétravail, etc.
Workflow: Solo VS collaboratif
Le flux de travail ou workflow peut varier en fonction de si nous travaillons seul ou en collaboration, localement sur notre ordinateur ou hébergé dans les nuages.
!PRENNEZ GARDE! - ne jamais placer votre REPO sur un drive nuagique comme Google drive ou Microsoft Cloud. Utilisez plutôt le site GitHub conçu pour ce faire sans quoi vous risquez (assurément) de perdre des données.
Prenons le temps de bien comprendre le REPO (abréviation du terme répertoire ou repository en anglais).
Tel que défini plus haut, le REPO est le dossier d’un projet contenant toute ses parties que nous confions à un VCS comme Git. La seule tâche du VCS est de consigner les changements (delta) des fichiers dans le temps.
- Regardons ensemble les différents cas de figure
* si nous travaillons seul et de façon locale: nous aurons un répertoire de travail, une scène de montage et notre REPO local.
* si nous travaillons seul et choisissons d’héberger notre REPO sur GitHub: nous aurons un répertoire de travail, une scène de montage, notre REPO local ainsi que le REPO hébergé.
* si nous travaillons en équipe: chaque membre de l’équipe aura son répertoire de travail, sa scène de montage et son REPO local. Il aura un seul REPO hébergé, ce que nous avons précédemment appelé le blessed REPO qui sert de REPO officiel du projet.
Lorsque l’on travaille en équipe, chaque personne devra commencer par faire un clone du REPO hébergé sur son ordinateur qui deviendra son REPO local. Ensuite, chaque membre de l’équipe travaillera sur un aspect ou feature différent dans son répertoire de travail local. Lorsqu’une personne sera satisfaite de son travail et qu’elle voudra commettre son avancement, elle fera un commit à son REPO local. Le commit du REPO local vers le REPO hébergé s’appelle un merge et se fait idéalement lorsque le travail du feature est accompli et que la personne responsable de ce feature le considère prêt pour être intégré au projet commun.
Par la suite, les autres membres de l’équipe peuvent faire un pull pour mettre leur REPO local à jour avec le nouveau feature.
Comprendre les branches
Les branches sont en quelque sorte un univers parallèle. Il consiste une copie du REPO local. Le principal attrait d’utiliser une branche est de permettre un espace sécuritaire où faire des essais de code risqués qui pourrait autrement briser le reste du code qui fonctionne. On peut faire une branche pour essayer de coder une nouvelle fonction. Dans R, on peut faire une nouvelle branche pour essayer d’illustrer nos résultats dans des graphiques différents suite à des propositions reçues par nos collègues par exemple. Les branches sont sans risque puisque nous pouvons abandonner la branche à n’importe quel moment, sans conséquence à la branche principale ou MAIN, si le travail en cours ne convient pas.
3. Univers Git
Avant d’installer Git, vous pouvez d’abord vérifier s’il n’est pas déjà installé sur votre ordinateur à l’aide du terminal (Mac ou Linux) ou du cmd.exe (Windows). Nous verrons cette étape à la section 4. Les codes fournis dans le présent atelier sont des codes pour le Terminal et pourraient ne pas fonctionner sur Windows. Si c’est le cas, il suffit d’aller vérifier sur internet le code équivalent.
Autrement, vous pouvez simplement aller sur https://git-scm.com/downloads pour télécharger la version la plus récente pour votre système d’exploitation (le site web détecte automatiquement la version compatible pour vous).
Puisque le logiciel Git est essentiellement invisible, il est préférable de se munir d’une interface graphique ou Graphic User Interface (GUI) en anglais. Ceci est un logiciel qu’on installe sur notre ordinateur de travail créé pour simplifier le travail avec Git en fournissant une interface visuelle pour l’utilisateur. Plusieurs GUI gratuit et payant sont disponibles pour les différents systèmes d’exploitation. On peut penser à GitHub Desktop, SourceTree, SmartGit, TortoiseGit, Git Extensions et GitUp pour n’en nommer que quelques-uns.
GitHub Desktop
Nous verrons ce GUI dans la deuxième partie de l’atelier pratique.
Ce GUI simple est gratuit et fonctionne sur tous les systèmes d’exploitation.
SourceTree
Ce GUI gratuit fonctionne sur Mac et Windows et a été créé par Atlassian, une compagnie qui fournit des outils de travail pour des équipes de millier d’entreprises au travers du monde. Ils offrent également de bonnes informations et guides sur l’utilisation de Git.
SourceTree offre un affichage simple, tout comme GitHub Desktop, mais est bonifié par l’ajout d’un arbre visuel des branches de travail qui simplifie le suivi des commits au fil du temps par une représentation visuelle efficace.
GitHub
GitHub est une plateforme open-source où partager et publier du code. Il sert de serveur où héberger nos REPO. Chaque utilisateur doit se créer un compte pour pouvoir cloner un REPO existant, téléverser son REPO local ou merger sont travail à un REPO d’un travail en cours (une contribution).
Il existe maintenant une panoplie de serveur alternatifs où héberger son projet tel: GitLab, BitBucket, LaunchPad, SourceForge, Beanstalk, Apache Allura, Git Kraken, Git Bucket, etc… Chacun a ses forces et ses faiblesses respectives. Je vous invite à consulter le site web suivant pour une charte comparative : https://www.softwaretestinghelp.com/github-alternatives/.
SSH Keygen
Le Secure Shell Protocol (SSH) keygen permet d’authentifier une personne qui souhaite se connecter à un serveur en ligne.
Avec une clef SSH, une personne peut se connecter à GitHub sans avoir à entrer son nom d’utilisateur et son mot de passe à chaque visite. La clef SSH peut aussi être utilisée pour signer les commits. Le SSH est essentiellement le fichier d’une clef privée sur notre ordinateur.
Vous pouvez en lire d’avantage sur : www.docs.github.com.
R/RStudio
Il y a moyen d’utiliser l’interface de R/RStudio pour utiliser les commandes Git. C’est à peu près aussi intuitif que d’utiliser le Terminal ou cmd.exe (donc pas du tout intuitif pour un néophyte).
Pour cette raison, nous n’explorerons pas davantage cet outil dans R/RStudio mais sachez qu’il est possible de le faire. Si vous souhaitez l’utiliser, vous devrez activer la library(usethis) suivi par la commande usethis::use_git().
4. Atelier
Partie 1 : Utilisation de Git au travers du Terminal
Étape 1:
On commence d’abord par ouvrir le Terminal. Sur un Mac, le Terminal se trouve dans Application, Utilitaire. Sur Windows, ouvrez le menu démarrer, inscrivez cmd dans la barre de recherche et sélectionnez Command Prompt. L’icône ressemble à du code en blanc sur un fond noir dans les deux cas:


Étape 2:
On vérifie la version de Git afin de savoir s’il faut la mettre à jour: git -v
Si git est installé, le Terminal nous rapporte sa version:

Étape 3:
On vérifie le working directory ou répertoire de travail dans lequel nous nous trouvons actuellement avec la commande pwd
Par défaut, nous serons dans le répertoire du User actif.
Étape 4:
Pour changer le répertoire, soit on glisse le dossier dans le Terminal, soit on inscrit écrit le chemin à l’aide de la commande *change directory cd Desktop par exemple qui nous pointe vers le bureau de l’utilisateur actif. On peut ensuite réinscrire pwd pour valider que le changement a bel et bien été fait.
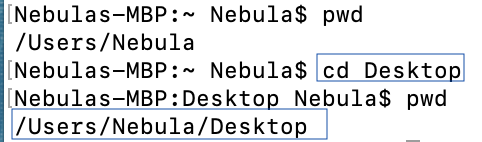
Étape 5:
Nous pouvons ensuite créer le dossier du Projet une fois que nous somme dans le bon répertoire de travail. Notez qu’on ne parle pas encore ici d’un REPO puisque ce dossier pour notre Projet n’est pas encore pris en charge par Git.
On utilise la commande mkdir pour make directory afin de créer le dossier du Projet qui deviendra notre REPO:
mkdir "Nom"
- où le Nom correspond au nom du dossier ou du Projet.
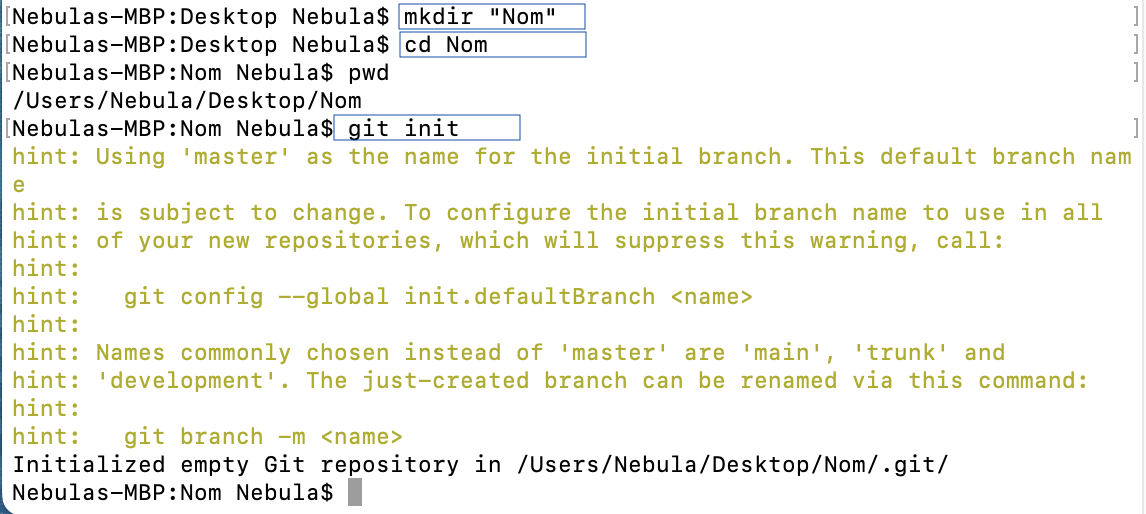
Étape 6:
On doit ensuite se diriger dans ce nouveau dossier avant de dire à Git de prendre en charge le dossier pour son suivi transformant ainsi le dossier en REPO:
cd Nom suivi de git init
Le Terminal nous informe que la branche se nomme ‘master’ et qu’il est possible de le modifier. Le Terminal nous mentionne également que le REPO est bel et bien initialisé et à quel emplacement.
 #
#
Étape 7:
On peut utiliser le Terminal pour ajouter des fichiers grâce à la commande touch.
touch .gitignore devrait être le premier fichier que vous devriez ajouter à tout REPO. Il permet d’y inscrire tous les fichiers que nous ne voulons pas que Git suivent. On peut trouver une liste complète des fichiers à ignorer sur internet en fonction du logiciel qu’on utilise pour coder. Cela permet d’ignorer des fichiers essentiels à l’utilisation local d’un logiciel qui sont inutile au projet.
Veuillez consulter le site web suivant pour copier-coller dans .gitignore ce qui doit être ignoré lorsqu’on utilise R: https://github.com/github/gitignore/blob/main/R.gitignore
Étape 8:
Une commande utile pour lister les documents présents dans le REPO est ls -a
Le Terminal nous retourne 4 items: ., .., .git et .gitignore
Étape 9:
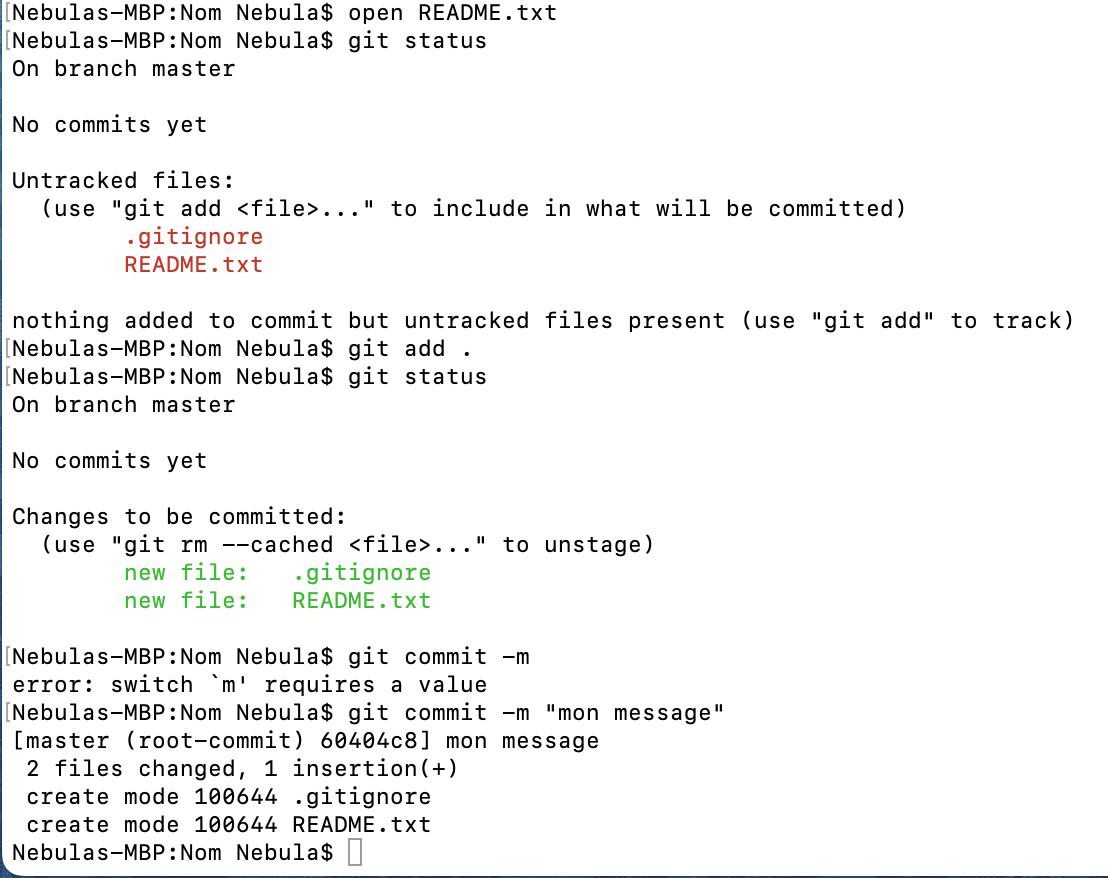
Ajoutons un fichier .txt dans lequel nous allons écrire un texte pour décrire l’objectif du projet avec toute instructions ou directives utile pour quelqu’un de nouveau au projet:
touch README.txt suivi de open README.txt
Inscrivez le texte que vous voulez et sauvegardez.
Maintenant que notre projet contient des fichiers, nous allons procéder à notre premier COMMIT.
Débutons par visualiser l’état de notre travail avec la commande git status
Le Terminal nous diras qu’il n’y a eu aucun commit à date en plus de lister les Untracked files en rouge.
Il faut utiliser git add pour ajouter les fichier un a un ou tous ensemble dans la scène de montage avant de procéder au COMMIT:
git add . pour ajouter l’ensemble des fichiers ou git add (file path) pour ajouter les fichiers un à un.
Si on utilise git status de nouveau, le Terminal nous renvoi qu’il n’y a toujours pas eu de commits en plus de nous indiquer en vert le nom des fichiers dans la scène de montage.
Après validation, si nous sommes satisfait de ce qu’il y a dans la scène de montage, nous pouvons procéder au commit avec git commit -m "MON MESSAGE"
À noter que le texte entre les guillemets “” est le message que vous inscrivez pour chaque commit.
Il est IMPORTANT d’écrire un message détaillé faisant en sorte que vous ou un collègue serez en mesure de retracer et de comprendre les changements impliqués avec ce commit même 2 ans plus tard.
Étape 10:
Maintenant que votre premier commit est fait, toute modification aux fichiers existants ou tout ajout ou retrait de fichier sera suivi par Git. Sentez-vous à l’aise de créer de nouveaux commits à chaque fois que vous franchissez un point de non-retour pour lequel que vous jugez important de laisser une trace.
Amusez-vous, ouvrez le README.txt, faites une modification, sauvegardez et faites un commit. Pour visualiser l’historique des commits, utilisez la commande git log. N’hésitez pas de consulter les autres commandes disponibles sur internet.
Partie 2 : Utilisation de GitHub Desktop
Étape 1:
Téléchargez le GUI GitHub Desktop en allant sur le site web : https://desktop.github.com/
Étape 2:
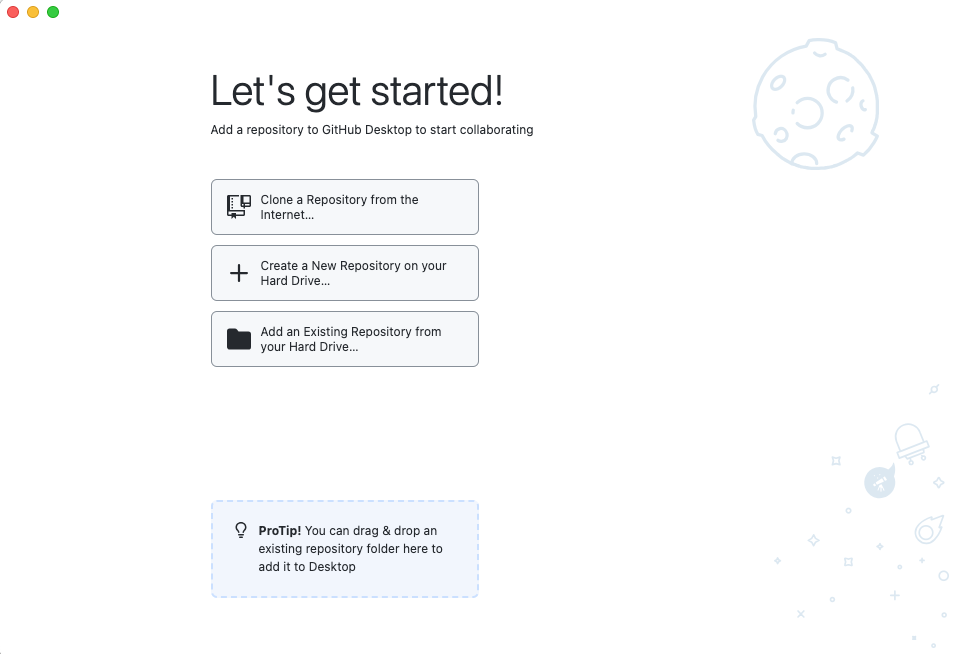
Ouvrez l’application (l’icône du chat violet)
 GitHub Desktop vous offrira trois choix:
GitHub Desktop vous offrira trois choix:
* Cloner un REPO de l’internet
* Créer un nouveau REPO local sur notre disque dur
* ajouter un dossier existant de notre ordinateur
Étape 3:
Pour les besoins de l’atelier, choisissons de créer un nouveau REPO local (2ème choix)
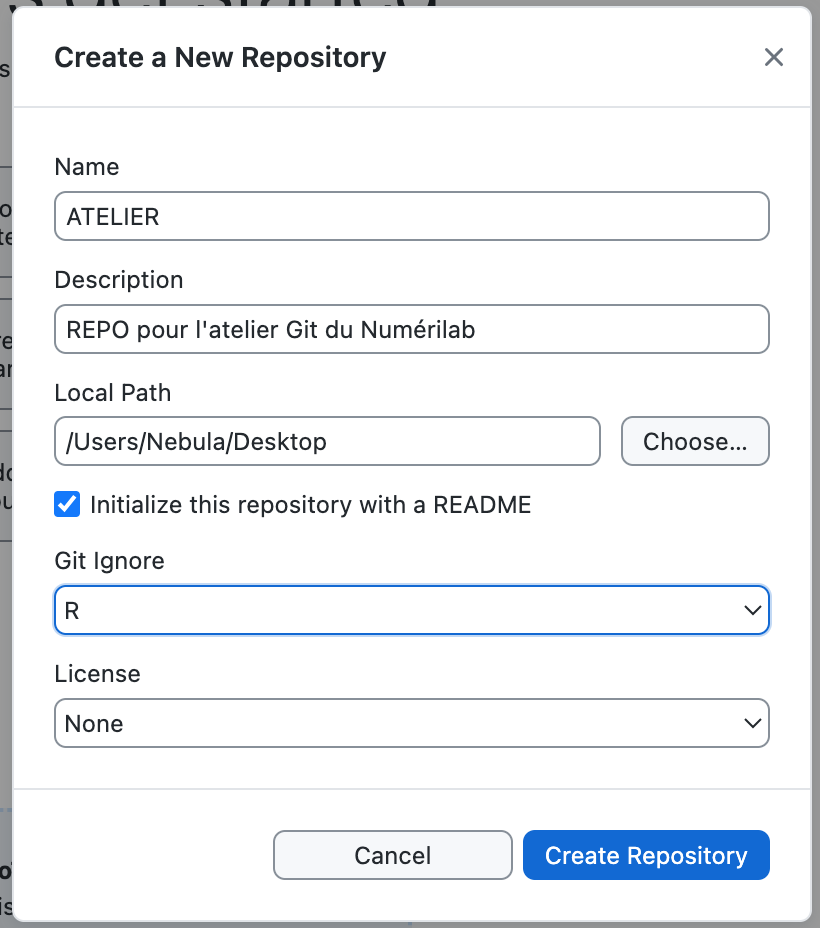
Il faudra donner un nom au REPO. Je propose de vous inspirer du nom de votre projet (ATELIER est ce que je vais inscrire dans cet exemple). La description est facultative mais pourrais être utile à démêler des projets similaires.
Le Local Path est l’emplacement où nous souhaitons créer le REPO sur notre ordinateur. (ici je pointe vers le bureau Desktop). Aidez-vous du bouton Choose pour naviguer ailleurs à l’emplacement souhaité.
Je vous recommande de sélectionner la case pour initialiser un document README. Vous pourrez ensuite y laisser une description du projet ainsi que des instructions détaillées sur la méthode de travail pour maintenir un certain ordre dans le répertoire et faciliter la recherche de dossier par exemple.
GitHib Desktop offre un menu déroulant pour ajouter d’emblée les fichiers devant être ignorés par Git. Allez sélectionner R.
Sélectionner une licence au besoin et cliquez sur Create Repository.
Étape 4:
GitHub Desktop aura créé un nouveau dossier à l’emplacement souhaité. (Dans cet exemple, le dossier ATELIER a été créé sur mon Desktop).
Si vous l’ouvrez, vous verrez le fichier README.md que nous avons demandé à GitHub de créer précédemment. Vous pouvez l’ouvrir avec R/RStudio pour y ajouter tout le texte que vous voulez pour vous assurer d’une utilisation harmonieuse du REPO par vous-même, dans 5 ans, ou par les membres de l’équipe si vous travaillez en collaboration.
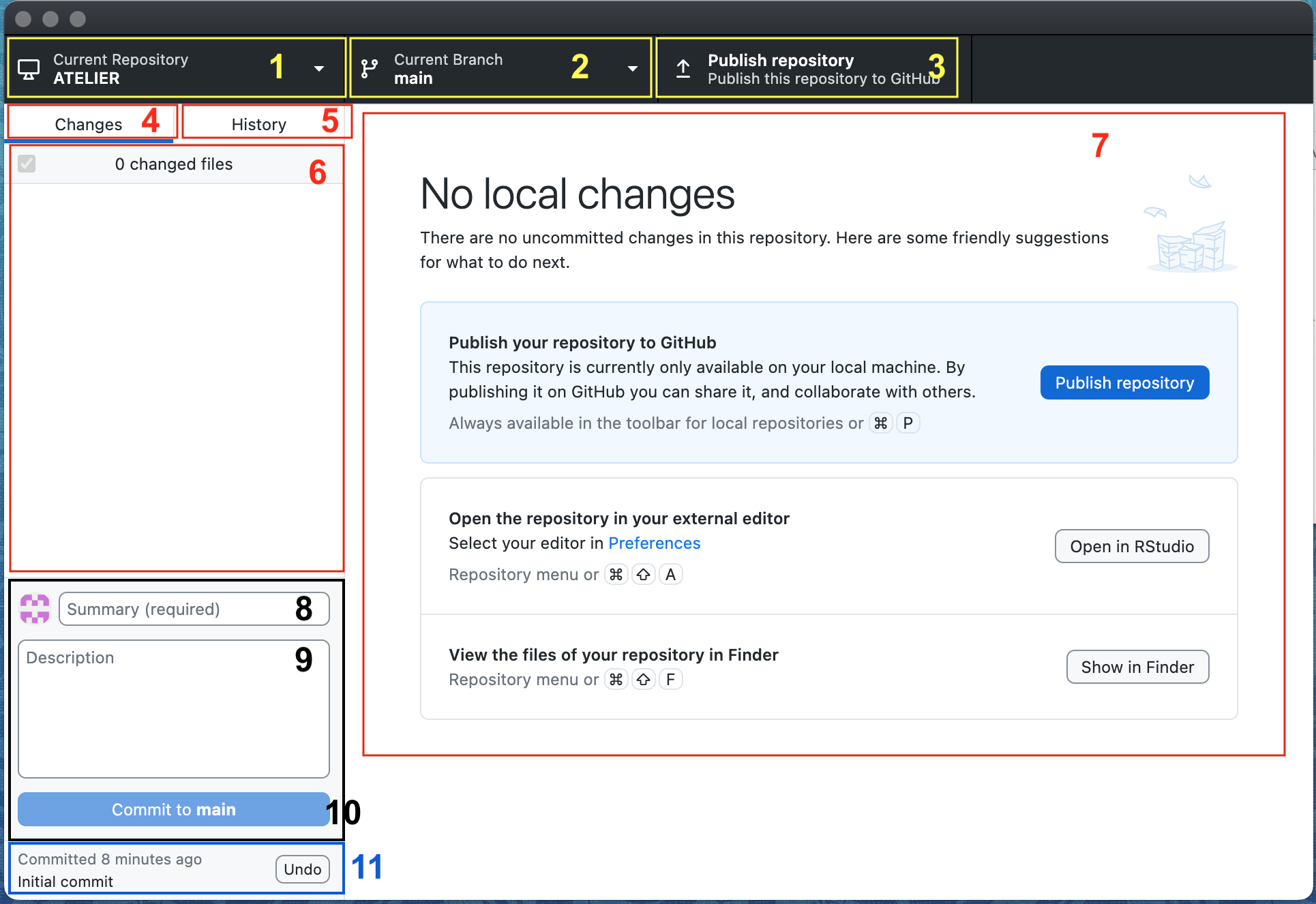
Si nous détournons notre attention au logiciel GitHub Desktop, nous verrons différente sections ou case que nous allons décortiquer (voir image ci-jointe):
L’encadré 1 et 2 permettent de naviguer vers le bon répertoire de travail:
* 1. Indique dans quel répertoire on se trouve;
* 2. Indique la branche active;
L’encadré 3 permet de prendre notre REPO actif (point 1 et 2) et de le téléverser sur notre REPO hébergé:
* 3. Lien rapide pour téléverser le REPO sur GitHub;
L’encadré 4-5-6-7 concernent l’historique des changements:
* 4. Indique les changements depuis le dernier commit;
* 5. Indique l’historique des commits;
* 6. Lorsque les changements (point 4) est sélectionné, cette section liste les deltas, soit les changements apportés aux dossiers depuis le dernier commit,
Lorsque l’historique (point 5) est sélectionné, cette section liste les commits du plus récent au plus vieux avec les messages et l’identifiant unique de chaque commit;
* 7. présentement vide, cette section nous permet de visualiser les changements d’un fichier entre les commits, nous verrons un exemple plus loin;
La section 8, 9 et 10 servent à effectuer un commit :
* 8. endroit où indiquer le titre du commit;
* 9. endroit où laisser un message suffisamment détaillé pour pouvoir retracer les changements effectués au travers du temps;
* 10. bouton pour commettre;
* 11. bouton pour défaire le commit
Étape 5:
Procédons à un premier commit à l’aide des cases 8, 9 et 10.
Ajoutez ensuite tous les fichiers ou dossiers que vous souhaitez dans votre REPO. GitHub Desktop fera apparaitre presque instantanément les changements dans l’onglet changes (encadré 4). Procédez à un autre commit.
Pour cet exemple, j’ai ajouté un fichier image.jpeg, un document word Jingle Bells Lyrics.docx en plus d’ouvrir le README.md pour y ajouter des modification aux instructions inscrites préalablement.
Si nous sélectionnons l’onglet 4 Changes, nous verrons un symbole + dans un carré vert à droite de image.jpeg et de Jingle Bells Lyrics.docx. Ceci indique que les fichiers sont nouveaux depuis le dernier commmit.
Le fichier README.md aura plutôt un carré jaune avec un point en son centre pour indiquer qu’il a subi des modifications depuis le dernier commit. Si nous cliquons sur le nom du dossier README.md, GitHub Desktop nous montreras les changements dans l’encadré 7 comme suit:
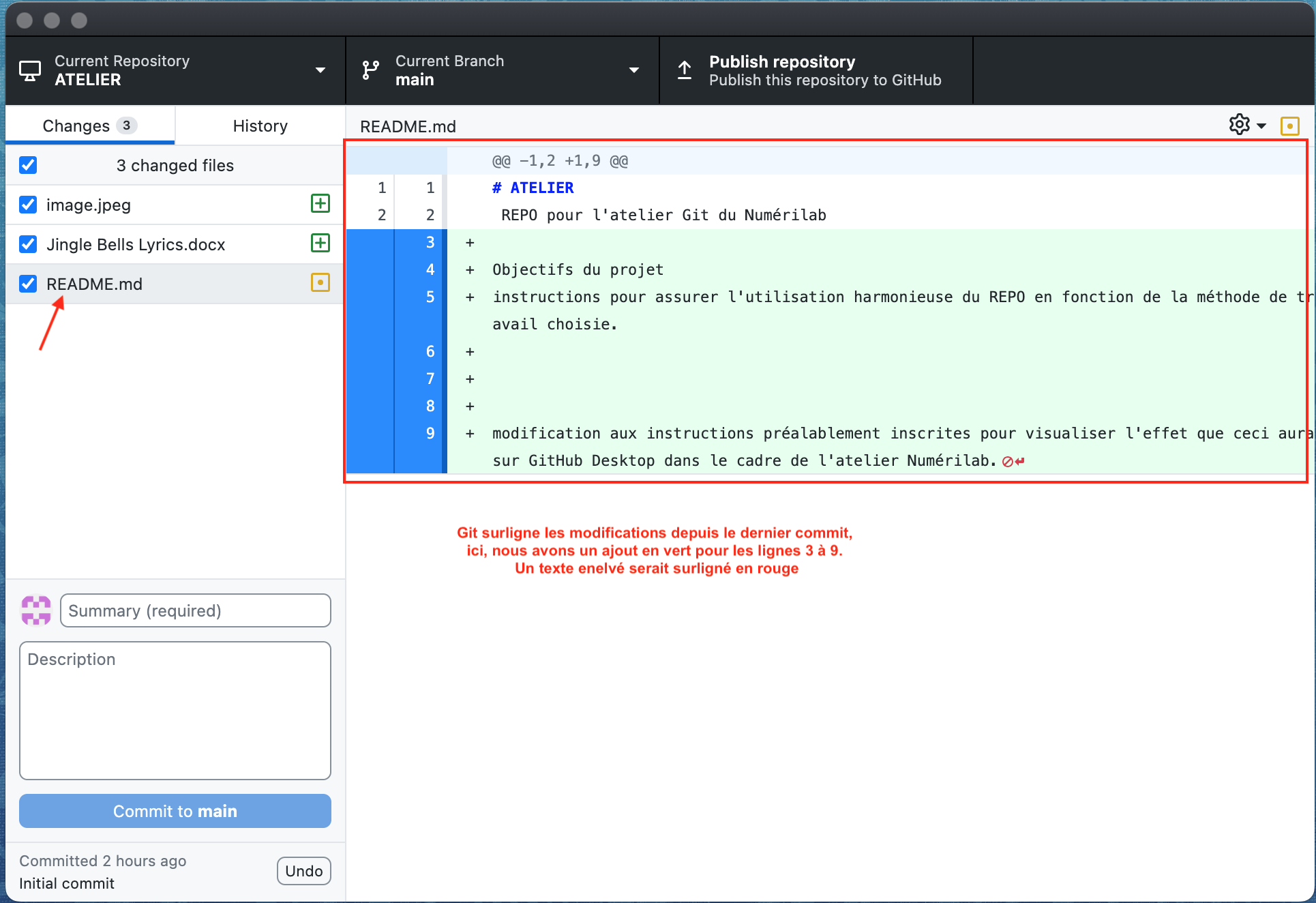
Le fichier Jingle Bells Lyrics.docx indiquera qu’on ne peut pas visualiser les changements puisqu’il s’agit d’un fichier de type binaire (voir l’image à l’étape 6 pour un exemple du message que Git nous renvoie). N’ayez crainte, Git suit quand même les changements mais il n’arrive pas à discerner exactement la nature des changements comme il peut le faire un fichier non-binaire (un .txt ou .md par exemple).
Pour les fichiers .jpeg, il sera possible de visualiser les changements par différents moyens dans la case 7 : 2-up, Swipe, Onion skin ou Difference.
* 2-up : montre l’ancienne version et la nouvelle côte à côte;
* Swipe : affiche une barre que nous pouvons glisser pour voir les changements progressif au fil du temps;
* Onion skin : même principe que l’option Swipe mais la différence peut être observé à l’aide du changement d’opacité des images qui fondent de l’une à l’autre;
* Difference : seul l’élément ajouté sera affiché sur un arrière-plan noir.
Étape 6:
Allons maintenant explorer l’onglet Historique à la case 5.
Tel que mentionné, l’onglet Historique permet d’afficher la liste des commits au fil du temps à la case 6 ainsi que les détails des changements à la case 7.
Voici un aperçu :
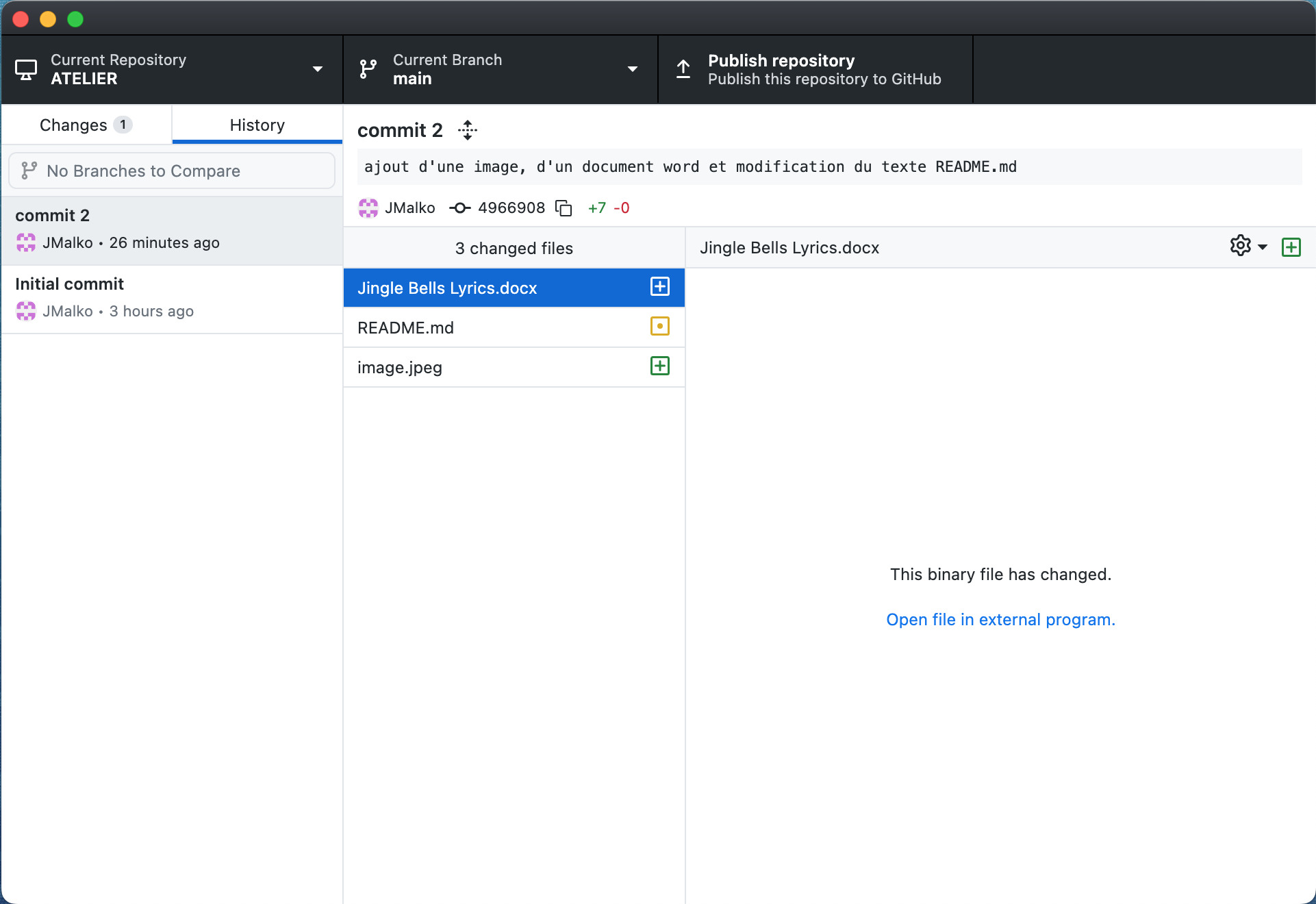
La case 7 nous informe que nous avons 2 commits à date et inscrit le message du commit sélectionné à la case 6. Il nous informe de l’identifiant unique du commit et de l’identité de la personne ayant commis les changements (le symbole rose avec la mention JMalko, soit mon identifiant créé lorsque j’ai installé Git).
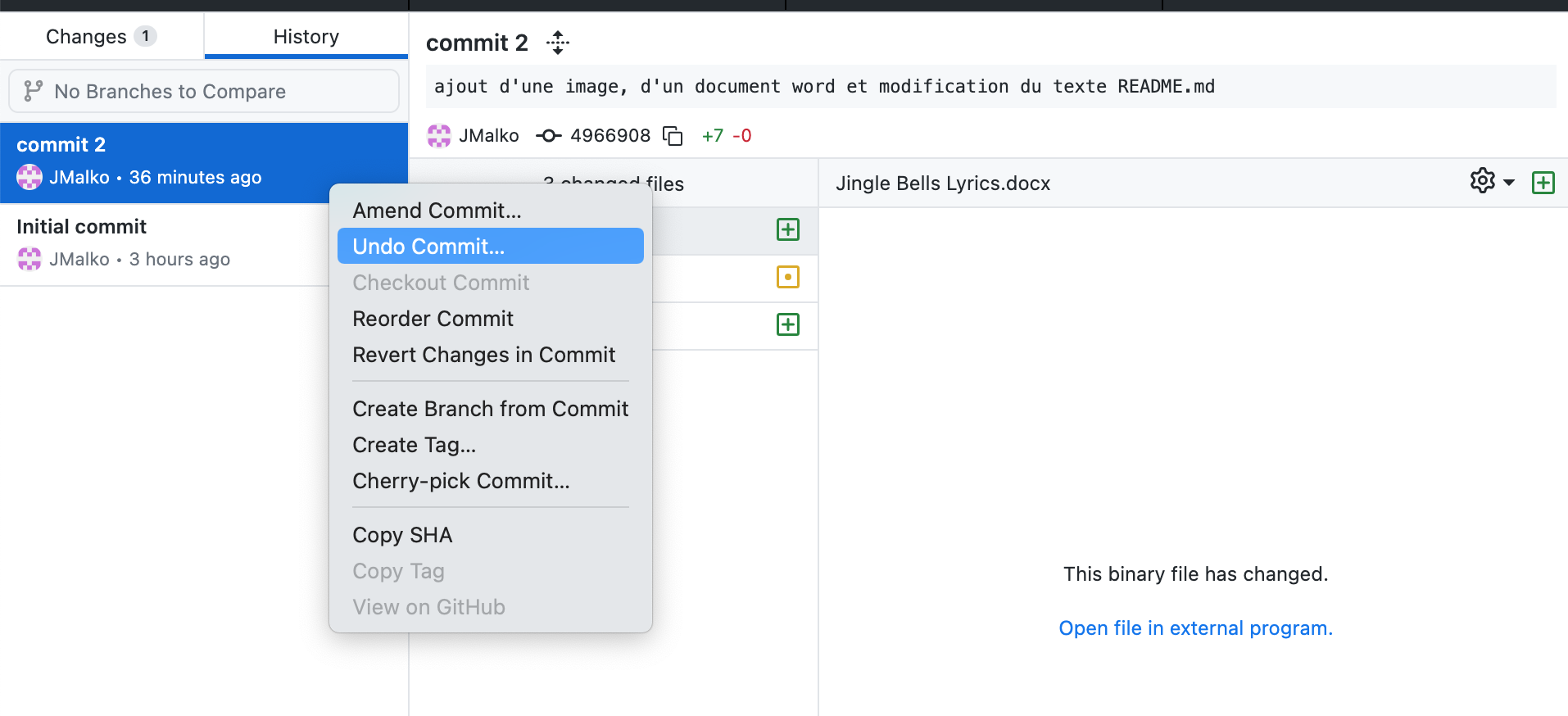
Étape 7: Gestion des commits:
Il est possible d’effacer, de changer l’ordre, de créer une branche ou de faire un amendement aux commits en effectuant un click droit sur le commit que l’on souhaite modifier à la case 6 (voir image ci-dessous).
Félicitations!
Vous êtes maintenant outillés pour vous aventurer à utiliser Git
pour faciliter le suivi de vos fichiers de votre projet au fil du temps!
Astuces :
* n’hésitez pas de créer une nouvelle branche lorsque vous avez à travailler du code risqué qui pourrait mettre en péril le travail déjà accompli. Advenant que le nouveau code ne fonctionne pas, vous pouvez abandonner la branche sans répercussion sur votre branche principale. Vous pouvez avoir autant de branches que vous le souhaitez, elles n’alourdiront pas votre système.
* ne téléversez JAMAIS votre REPO sur un serveur nuagique comme Microsoft cloud ou Google Drive. Utilisez plutôt un serveur conçu pour gérer des REPO suivi par Git sans quoi vous rencontrerez assurément des problèmes comme de la perte de données.
Conclusion
Les points à retenir:
1. Git en soi n’est pas un logiciel à partir duquel travailler; c’est une série d’instructions que nous pouvons donner à l’ordinateur par le biais du Terminal (ou du Command Prompt dans Windows) ou à partir de d’autres logiciels GUI.
Git est invisible et sert de journal où répertorier et faire le suivi des changements (delta) entre les versions des fichiers dans le REPO.
2. Une fois que votre dossier est pris en charge par Git, continuez de travailler comme vous le faisiez avant, en ouvrant votre projet à l’aide du dossier pour y apporter les modifications que vous voulez.
Par la suite, utiliser le Terminal ou un GUI pour effectuer les commits, changer de branches, téléverser le REPO vers GitHub, etc…