Keras et les grands modèles de langage (LLM, e.g. ChatGPT)
Charles Martin
Octobre 2023
- Introduction
- Les entrailles d’un modèle d’apprentissage profond
- Faire de l’apprentissasge profond sous R
- Sur-ajuster et sous-ajuster
- Implications pour les données
- Un premier example
- Comment Keras peut-il comprendre le language humain
- Conclusion
- Références
Introduction
Bonjour tout le monde et bienvenue à ce troisième Numérilab sur l’apprentissage automatique. À cette occasion, nous nous attaquerons à nouveau à l’apprentissage profond (deep learning) à l’aide de la librairie Keras. Mais plutôt que de s’intéresser au traitement d’images, nous verrons aujourd’hui comment ces modèles traitent le texte. Comment ils peuvent classer des textes (pensez aux analyses de sentiment) et comment ils peuvent générer du nouveau contenu (comme le fait si bien ChatGPT)
Pour mettre la table, commençons par se donner quelques définitions associées à l’intelligence artificielle, question de partir sur de bonnes bases.
Habituellement, lorsque l’on parle d’intelligence artificielle (IA), nous faisons référence à n’importe quelle technique où l’ordinateur fait quelque chose pour nous, de façon automatisée. Il s’agit d’un terme très large.
Plus spécifiquement, nous parlons d’apprentissage automatique (machine learning, ML) lorsque l’on présente à l’ordinateur une série d’entrées et une série de sorties, et qu’il se charge lui-même de trouver la meilleure correspondance, la meilleure fonction reliant les deux. La plupart des analyses statistiques en écologie tombent dans cette catégorie (régression linéaire, ANOVA, random forests, etc.)
Enfin, lorsque l’on parle d’apprentissage profond (deep learning), on parle habituellement de techniques d’apprentissages automatique où les représentations des données sont reliées en couches successives dans ce que l’on appelle un réseau neuronal (neural network)
Contrairement à la croyance populaire, le profond dans l’apprentissage profond ne fait pas référence à la qualité de la compréhension. Il fait plutôt référence aux différentes couches de représentation qui sont empilées les unes sur les autres.
De par son niveau plus avancé, cet atelier assume que vous connaissez certaines bases de la manipulation de données et de la visualisation de données dans R. J’essaierai néanmoins de garder les choses le plus simple possible.
Si jamais vous avez besoin d’un rappel concernant ces deux sujets, je vous recommande de consulter ces ateliers classiques du Numérilab :
- https://numerilab.io/fr/ateliers/RapidDataViz
- https://numerilab.io/fr/ateliers/RapidDataManip
Les entrailles d’un modèle d’apprentissage profond
L’architecture
Comme discuté précédemment, les modèles d’apprentissage automatique tentent de trouver la meilleure correspondance entre les entrées (inputs) et les sorties (outputs). En apprentissage profond, on appelle souvent ces sorties les cibles.
Dans un modèle d’apprentissage profond, les entrées passent par une première couche de transformations, qui produit des sorties qui sont utilisées comme entrées dans une seconde couche et ainsi de suite, jusqu’à la couche finale qui tente de prédire une valeur cible, basée sur les entrées fournies.
Chaque couche contient une série de poids, au même titre que les coefficients de la régression ou de l’analyse en composantes principales. Mais contrairement à ces modèles simples, un modèle d’apprentissage profond contiendra souvent des millions de paramètres à optimiser.
Deux fonctions importantes
Avant d’arriver à la partie optimisation, nous devons d’abord définir comment notre modèle d’apprentissage profond pourra mesurer à quel point ses prédictions sont proches ou éloignées des cibles originales.
Nous appellerons cet outil la fonction objectif (objective function). Vous verrez aussi le terme fonction de perte (loss function) ou fonction de coût. Il s’agit d’un seul et même concept, mais la fonction objectif pourrait être minimisée ou maximisée selon le type de problème. Le terme est plus générique que fonction de perte, qui elle doit être absolument minimisée.
Dans le modèle de régression linéaire classique, la fonction objectif serait $\frac{1}{n} \sum(y-\hat{y})^2$, soit la somme des carrés des résidus.
Comme les modèles d’apprentissage profond sont très versatiles, nous aurons beaucoup plus d’options. Pour les problèmes de type régression, nous utiliserons effectivement la somme des carrés des résidus, mais dans le cas des problèmes de catégorisation, nous utiliserons probablement l’entropie croisée.
L’entropie croisée est une mesure provenant de la théorie de l’information, qui évalue la distance entre deux distributions de probabilités. Allons-y d’un petit exemple pour clarifier ce concept. Si notre variable cible est une variable binaire pouvant prendre les valeurs vrai ou faux, elle sera encodée comme un vecteur soit [1,0] pour les valeurs vraies ou [0,1] pour les valeurs fausses (nous reviendrons plus loin sur cette stratégie d’encodage).
Si une observation est vraie [1,0] et que notre modèle prédit les probabilités suivantes [0.75,0.25], l’entropie croisée entre les deux distributions sera mesurée comme -(1log(0.75) + 0log(0.25)) = 0.288. Si au contraire notre modèle se trompe beaucoup pour cette observation en particulier, par exemple avec [0.3,0.7], l’entropie croisée entre les deux distributions sera -(1log(0.3) + 0log(0.7)) = 1.204.
Maintenant que notre modèle est capable de mesurer à quelle distance il se trouve de sa cible, il devra aussi avoir une façon de modifier ses coefficients, afin d’essayer de se rapprocher de cette cible. Habituellement, lorsque l’on parle d’apprentissage profond, on s’attend à ce que la fonction d’optimisation suive l’algorithmique du gradient stochastique (stochastic gradient descent, SGD).
Dans le cas simple où on a un seul paramètre à optimiser, un algorithme de descente de gradient tente de déterminer le gradient (i.e. la dérivée) de chaque côté de sa position actuelle en bougeant légèrement la valeur de son paramètre à la hausse et à la baisse. Il choisira ensuite le côté vers lequel la fonction objectif s’améliore et modifiera la valeur du paramètre d’une quantité arbitraire (le taux d’apprentissage, learning rate) dans cette direction. Il répétera cette opération jusqu’à atteindre un point où la fonction objectif ne s’améliore plus.
Dans un contexte avec des milliers, voire des millions d’observations, l’évaluation du gradient implique d’évaluer l’entièreté du jeu de données deux fois pour chaque petit ajustement d’un paramètre, ce qui peut devenir très lourd. C’est pourquoi les modèles d’apprentissage profond utilisent plutôt l’algorithme de gradient stochastique. Son fonctionnement est exactement le même, mais chaque itération s’effectue sur un petit sous-ensemble aléatoire du jeu de données. L’algorithme aura besoin de plus d’itérations pour arriver à une solution optimale car sa descente sera bruitée par l’échantillonnage effectué à chaque étape, mais, chaque itération se fera beaucoup plus rapidement, ce qui au final, permettra d’accélérer l’ajustement du modèle.
L’autre problème qu’un vrai modèle aura à son étape d’ajustement c’est qu’il ne contient pas un paramètre, il en contient habituellement des milliers ou souvent des millions. Il devient donc aussi extrêmement lourd de réajuster le modèle entier autant de fois qu’il y a de paramètres à ajuster. Heureusement pour nous, des informaticiens astucieux ont découvert une stratégie pour effectuer cette tâche efficacement dans un réseau neuronal à l’aide d’un algorithme nommé la rétropropagation (backpropagation). Les détails de cet algorithme, basé sur sur la dérivation en chaîne, vont bien au delà de ce qu’il est utile de discuter dans cette introduction. Il est surtout important de savoir que c’est cette percée qui a permis à l’apprentissage profond de devenir ce qu’il est aujourd’hui. Il existe plusieurs implémentations différentes de l’algorithme de rétropropagation, mais à moins de se lancer dans des modèles personnalisés allant au delà des architectures classiques, l’optimisateur rmsprop sera votre meilleur choix.
Que retrouve-t-on à l’intérieur d’une couche?
Finalement, le dernier morceau d’information nécessaire avant de se lancer dans la programmation est : que retrouve-t-on dans une couche de réseau neuronal?
Une couche est définie par 3 éléments : ses entrées, ses unités cachées et ses sorties. Dans une couche dense (la majorité de celles que nous verrons aujourd’hui), chaque unité cachée reçoit chacune des valeurs entrées et chaque unité cachée est connectée à chaque valeur de sortie.
Par exemple, si on considère une couche avec 3 entrées, 3 unités cachées et 2 sorties, chacune des unités cachées aura 3 valeurs en entrée pour faire ses calculs et 2 valeurs en sorties. Les 2 calculs de sorties recevront quant à eux 3 valeurs chacun.

Et voici un autre aspect clé des modèles d’apprentissage profond : plutôt que d’utiliser des combinaisons linéaires dans leurs calculs, ils utilisent des fonctions d’activation non-linéaires. Se faisant, ils ouvrent un espace de représentation auquel ils n’auraient pas accès en empilant des couches de transformations linéaires.
Il existe une multitude de fonctions d’activation prévues à cette fin, la plus commune étant la fonction relu (un redresseur, *Rectified Linear Unit**), qui comprend une partie plate et une partie avec une pente :
 Laughsinthestocks, CC BY-SA 4.0
Laughsinthestocks, CC BY-SA 4.0
Au bout de notre réseau (i.e. à la dernière couche), nous utiliserons aussi différentes fonctions d’activation, par exemple la fonction sigmoïde lorsque l’on prédit des probabilités, ou simplement aucune fonction d’activation dans des problèmes de type régression.
Faire de l’apprentissasge profond sous R
L’installation de Keras
À l’heure actuelle, la meilleure librairie d’apprentissage profond est sans aucun doute Keras. Le problème majeur pour nous aujourd’hui est que cette librairie est constituée de code Python, alors que notre atelier se déroule en R.
Heureusement, il existe en R une librairie keras, qui effectuera le travail de traduction entre R et Python pour nous.
Vous devrez d’abord installer, comme normalement, la libraire keras sous R :
install.packages("keras")
Puis activez là :
library(keras)
Ensuite, vous devrez installer un mini-gestionnaire de code Python nommé miniconda :
reticulate::install_miniconda()
Enfin, une fois cette opération complétée, vous devrez installer la version Python du code de Keras, comme ceci :
install_keras()
Si jamais à cette étape ou à une des étapes suivantes vous obtenez un message d’erreur concernant un module Python manquant, vous pouvez consulter la liste des modules installés à l’aide de la commande :
reticulate::py_list_packages()
Et installer les modules manquants à l’aide de la commande py_install. Dans mon cas, j’ai dû installer manuellement les modules pillow et scypi :
reticulate::py_install("pillow")
reticulate::py_install("scipy")
Les étapes précédentes n’ont besoin d’être effectuées qu’une seule fois par ordinateur. La prochaine fois que vous voudrez utiliser Keras, vous n’aurez qu’à faire :
library(keras)
Hello World - tester votre installation
L’installation de Keras sous R peut être une aventure périlleuse. C’est pourquoi, avant de vous lancer dans quoi que ce soit d’autre, je vous conseille de copier-coller ce petit code de test et vous assurer que tout fonctionne correctement, sans erreur :
mnist <- dataset_mnist()
x_train <- array_reshape(mnist$train$x, c(nrow(mnist$train$x), 784)) / 255
y_train <- to_categorical(mnist$train$y, 10)
model <- keras_model_sequential() %>%
layer_dense(units = 256, activation = 'relu', input_shape = c(784)) %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 128, activation = 'relu') %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 10, activation = 'softmax')
model %>% compile(
loss = 'categorical_crossentropy',
optimizer = optimizer_rmsprop()
)
model %>% fit(
x_train, y_train,
epochs = 15, batch_size = 128,
validation_split = 0.2,
verbose = 0
)
Ce code pourrait prendre une minute ou deux à rouler, puisqu’il est en train d’apprendre à reconnaître des chiffres écrits à la main dans une série de petites images.
À propos des messages d’erreur Python
À vos premières expériences avec Keras, vous rencontrerez beaucoup de messages d’erreur cryptiques. Probablement plus qu’avec n’importe quelle librairie R par le passé.
Cela survient parce que les erreurs proviennent du code Python sous-jacent au code R. À mon avis, c’est l’aspect le plus désagréable de cette approche.
Dans mes essais-erreurs pour préparer cet atelier, j’ai réalisé que deux types étaient particulièrement récurrents :
(1) Mes données n’étaient pas en format matrice. Contrairement à la majorité des librairies R où on peut travailler avec des tableaux de données (data.frame, tibble) ou des matrices (matrix) de façon interchangeable, Keras ne fonctionne qu’avec un seul type d’objet : des matrices. Malheureusement, le message ne sera jamais clair à ce sujet, c’est à vous d’investiguer.
(2) Mes données n’étaient pas aux mêmes dimensions que la couche d’entrée de mon modèle. Encore une fois, vous obtiendrez un message d’erreur interne de Python, et non quelque chose de simple comme : vérifiez les dimensions de votre matrice, elles ne correspondent pas aux dimensions de la première couche de votre modèle.
Sur-ajuster et sous-ajuster
Un concept particulièrement important dans le domaine de l’IA est celui du sur-ajustement et du sous-ajustement. On dit d’un modèle qu’il est sous-ajusté si il n’extrait par le maximum possible des données fournies. Le modèle pourrait être amélioré si il contenait plus de paramètres, plus d’interactions, plus de temps pour apprendre, etc. Au contraire, un modèle sur-ajusté connaît un peu trop bien nos données. Il excelle avec nos données d’entraînement, mais échoue lamentablement lorsqu’on lui en présente de nouvelles. Il ne généralise par bien à l’extérieur de ce qu’il connaît déjà.
La ligne entre le sous-ajustement et le sur-ajustement est un mince fil sur lequel vous devrez danser chaque fois que vous travaillerez sur un problème d’apprentissage profond.
Implications pour les données
Il y a plusieurs points où on peut intervenir pour éviter le sur-ajustement.
Tout d’abord, au moment de préparer votre jeu de données. Vous devez vous assurer que votre jeu de données soit suffisamment varié, i.e. qu’il soit représentatif de la variabilité naturelle du phénomène que vous voulez étudier.
Les modèles d’apprentissage profond sont TRÈS efficaces et prendront tous les raccourcis possibles pour améliorer leurs prédictions. Ils VONT voir le petit collant avec un “C” sur vos tubes contrôles. Ils VONT reconnaître que toutes les photos terrain post-traitement sont prises une journée plus nuageuse que les pré-traitement.
La deuxième stratégie consiste à s’assurer de ne pas valider la performance du modèle sur les mêmes données que celles utilisées pour l’entraînement. Bien que ce soit une bonne pratique en général, elle est rarement nécessaire dans un contexte typique de régression ou d’ANOVA, mais ici, c’est extrêmement important.
Typiquement, votre jeu de données sera séparé en 3 parties :
- Les données d’entraînement, pour ajuster le modèle
- Les données de validation, utilisées par l’algorithme pour suivre sa progression
- Les données de test, utilisées pour mesurer la performance finale de votre modèle.
Les données de test sont nécessaires parce que, inévitablement, vous essaierez plusieurs configurations de couches et d’hyper-paramètres différentes, et à chacun de ces essais, une partie de l’information de vos données de validation percolera dans votre modèle. C’est pourquoi il faut se garder des données vraiment indépendantes pour le test final.
Afin de raccourcir cet atelier, l’étape de création et de validation des données de test sera escamotée, mais sachez qu’elle est tout de même extrêmement importante.
Un premier example
Après cette longue introduction, nous sommes maintenant prêt à créer notre premier modèle d’apprentissage profond.
Avant de se lancer dans des modèles interprétant le langage, commençons par un cas simple qu’on aurait pu résoudre par un modèle plus classique : prédire le type de couvert forestier à partir d’une série de variables géographiques.
Les données proviennent du défi Forest Cover Type Prediction challenge sur Kaggle.com (https://www.kaggle.com/c/forest-cover-type-prediction/).
Préparation des données
Après avoir chargé les données, nous avons 3 choses importantes à faire :
- Tout d’abord, supprimer les valeurs manquantes. On aurait aussi pu utiliser des techniques d’imputation, mais cela dépasse le cadre du présent atelier.
- Deuxièmement, on doit standardiser les variables quantitatives. Keras utilise beaucoup de passes-passes mathématiques pour travailler rapidement, et ces dernières fonctionnent beaucoup mieux avec de petites valeurs.
- Troisièmement, on doit modifier légèrement notre variable cible (Cover_Type). Puisque le code sous-jacent s’effectue en Python et que les tableaux Python sont indexés à partir de 0 plutôt que de 1 comme dans R (longue histoire…), il faut soustraire 1 à tous nos types de couverts.
Dans la vraie vie, on aurait exploré nos données, et probablement transformé certaines données pour faciliter la vie du modèle, mais pour un premier essai, ça ira.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.3 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
foret <- read_csv("data/foret.csv") %>%
drop_na() %>%
mutate(across(Elevation:Horizontal_Distance_To_Fire_Points, scale)) %>%
mutate(Cover_Type = Cover_Type-1)
Rows: 15120 Columns: 56
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (56): Id, Elevation, Aspect, Slope, Horizontal_Distance_To_Hydrology, Ve...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
La prochaine étape est de préparer nos données pour les passer en entrée au modèle. Tout d’abord, en enlevant la colonne ID (qui n’a pas d’interprétation biologique) et en enlevant la colonne Cover_Type, qui contient nos cibles. Il faut aussi explicitement convertir nos données en matrice :
x <- foret %>%
select(-Id,-Cover_Type) %>%
as.matrix()
La même opération doit être effectuée pour préparer nos cibles. Remarquez que l’on utilise pull et non select, puisque l’on veut un vecteur, et NON un data.frame à une colonne.
y <- foret %>%
pull("Cover_Type")
Votre premier réseau neuronal
Lorsque l’on prépare un modèle d’apprentissage profond, il est important de s’interroger sur la complexité du problème étudié. Et cette complexité doit être reflétée dans la structure du modèle que nous construirons. Pour le moment, nous tenterons la chance avec 3 couches densément connectées.
Pour définir notre modèle, il faut lancer la fonction keras_model_sequential, puis, en utilisant l’opérateur d’enchaînement, définir la séquence de couches que nous voudrons utiliser. Dans notre cas, 3 couches densément connectées, la première avec 100 unités cachées et la deuxième avec 50.
Comme expliqué plus haut, ces deux couches utiliseront la méthode d’activation “relu”.
Remarquez que pour la première couche, nous devons aussi définir les dimensions de la structure de données en entrée, mais en omettant la première dimension, qui représente le nombre d’observations. Pour toutes les autres couches, Keras calcule automatiquement la forme des entrées en se basant sur les sorties de la couche précédente.
Finalement, remarquez que notre dernière couche ne contient que 7 unités cachées, puisque notre cible comprend 7 différentes classes. On utilise pour cette dernière couche la fonction d’activation “softmax”, qui permet d’obtenir de belles probabilités entre 0 et 1 pour chacune des classes. La fonction softmax est l’extension en plusieurs catégories de la fonction logistique.
modele_keras <- keras_model_sequential() %>%
layer_dense(units = 100, activation = "relu", input_shape = ncol(x)) %>%
layer_dense(units = 50, activation = "relu") %>%
layer_dense(units = 7, activation = "softmax")
Une chose à savoir à propos des modèles Keras est que leur définition (le code ci-haut) n’est pas directement liée à leur compilation (i.e. leur transformation en code comme tel). La compilation se déroule dans une étape subséquente.
À l’étape de compilation (ci-dessous), il faut spécifier deux choses importantes pour notre modèle : le choix de la méthode d’optimisation (à moins de besoin spécifiques, on utilise rmsprop) et la fonction objectif. Comme expliqué plus haut, dans des problème de classification avec >2 catégories, le mieux est d’utiliser l’entropie croisée.
À cette étape, on peut aussi spécifier des mesures additionnelles pour lesquelles on voudrait obtenir un suivi durant l’entraînement. Ici, nous suivrons aussi la précision (accuracy), parce qu’elle est plus facilement interprétable que l’entropie croisée.
Contrairement à presque tout le reste de ce que vous faites en R, les objets Keras sont modifiés automatiquement. Nul besoin d’assigner le résultat dans notre objet de modèle. C’est un peu contre-intuitif pour les vétérans de R, mais c’est beaucoup plus efficace lorsque l’on travaille avec de très gros objets comme les modèles d’apprentissage profond.
modele_keras %>% compile(
optimizer = "rmsprop",
loss = "categorical_crossentropy",
metrics = c("accuracy")
)
Enfin, nous sommes prêts à entraîner notre modèle, à l’aide de la fonction fit. Au minimum, la fonction fit a besoin de deux choses : les données d’entrée, et les données cibles, que l’on a nommées ci-haut x et y.
Par contre, on ne peut pas passer directement le vecteur de cibles textuelles au modèle. Il doit être converti manuellement en valeurs catégoriques. Dans l’utilisation normale de R, on aurait fait cette opération avec la fonction as.factor, mais pour notre modèle, on doit utiliser la fonction to_categorical, fournie par Keras.
Dans les modèles linéaires classiques (régression, ANOVA, etc.), il est impératif au moment de l’encodage de laisser tomber un des niveaux, par exemple avec le dummy coding, sinon les opérations d’algèbre matriciel de la méthode des moindres carrés ne pourrons pas s’effectuer correctement. Ceci n’étant pas une contrainte les réseaux neuronaux, on peut alors utiliser le one-hot encoding, où on obtient une variable par niveau de la variable catégorique.
Variable originale :
| Animal |
|---|
| Poisson |
| Chat |
| Poisson |
| Chien |
Variables équivalentes en dummy-coding :
| Chat | Chien |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 0 | 0 |
| 0 | 1 |
(Remarquez qu’on doit déduire que l’animal est un poisson, quand les deux variables sont à zéro)
Variables équivalentes en one-hot encoding
| Poisson | Chat | Chien |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 0 | 0 | 1 |
Au moment de lancer la fonction fit, on doit aussi choisir le nombre d’époques (epochs) que cette phase d’entraînement effectuera. En inscrivant 30, on demande à Keras de passer à travers notre jeu de données 30 fois.
Si l’on désire, on peut spécifier, comme ici, la proportion de données à utiliser pour la validation du modèle à chacune des époques. Un nombre habituellement entre 20 et 30% fourni des résultats satisfaisants. On aurait aussi pu préparer manuellement un jeu de données de validation et le passer à l’argument validation_data.
Pour ne pas remplir des pages d’atelier avec des messages sur l’avancement de l’entraînement, j’ai aussi ajouté l’option verbose = 0, mais vous pouvez l’omettre sur vos ordinateurs.
history <- modele_keras %>% fit(
x,
y %>% to_categorical(),
epochs = 30,
validation_split = 0.25,
verbose = 0
)
Cette opération prendra quelques secondes à rouler sur un portable ordinaire.
Une fois l’opération complétée, on peut avoir un résumé du processus d’entraînement en regardant l’objet history :
history
Final epoch (plot to see history):
loss: 0.367
accuracy: 0.8544
val_loss: 0.5166
val_accuracy: 0.8013
La première chose à constater est que ce premier essai fait déjà un excellent travail. Il est difficile de se faire une tête avec les valeurs de la fonction objectif (loss), mais la précision du modèle (i.e. la fraction de sites correctement prédits;accuracy) est de 0.85 avec les données d’entraînement et de 0.80 avec les données de validation, que le modèle n’avait pas utilisées pour s’entraîner. On a donc un taux de succès de 80%!
Si on regarde le classement de ce défi sur Kaggle (https://www.kaggle.com/c/forest-cover-type-prediction/leaderboard), notre modèle serait parmi les 200 ou 300 premiers sur >1500 participants. Par ailleurs, gardez en tête en regardant le classement que certains scores ne sont probablement pas légitimes puisque, malheureusement, les observations utilisées par Kaggle pour évaluer la performance des modèles ont été accidentellement disponibles au public…
Une chose importante à vérifier est de savoir si notre modèle est sur- ou sous-ajusté. On peut s’en faire une idée en regardant l’évolution de notre fonction objectif à travers les 30 époques utilisées :
plot(history)
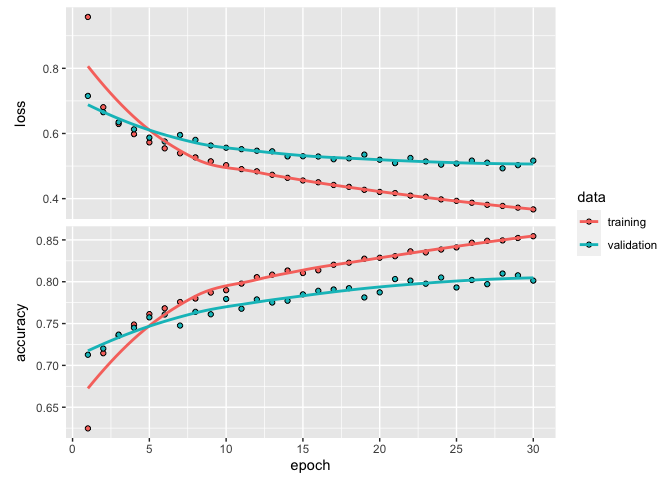
Comme vous le remarquez peut-être, ce premier modèle sur-ajuste rapidement nos données. On peut le voir en regardant la trace de la fonction d’objectif (loss), qui, déjà à la 5e époque performe mieux avec les données d’entraînement qu’avec les données de validation. Il s’agit là du premier signe d’un modèle sur-ajusté. Dans un modèle équilibré, les deux courbes auraient évolué en parallèle et convergé éventuellement vers leurs valeurs respectives.
On aurait probablement pu extraire un peu plus de performance de modèle en essayant différentes architectures (varier le nombre de couches, le nombre d’unités cachées, etc.). Il existe aussi des méthodes de régularisation permettant de réduire le sur-ajustement, mais nous n’aurons pas le temps d’aller jusque là aujourd’hui.
Comment Keras peut-il comprendre le language humain
Maintenant que nous avons vu à l’œuvre Keras avec des données propres et bien organisées en format rectangulaire, nous allons voir comment il peut traiter du texte.
Les méthodes d’encodage de texte
La préparation du texte pour le traiter dans un modèle d’apprentissage profond comprend habituellement deux étapes :
- Découper le texte en unités d’analyse (tokenisation en anglais)
- Encoder les unités d’analyse pour que le modèle puisse les traiter
Le découpage du texte en unités d’analyses (tokens) peut s’effectuer sur deux bases différentes. On peut le faire soit par mots, en séparant, entre autres, sur les espaces, ce qui pourra créer quelque chose qui pourrait ressembler à un vocabulaire au sens où on l’entend normalement. Ou soit en traitant chaque caractère comme une unité d’analyse. Cette approche, plus lourde, permet cependant au modèle une certaine créativité : il aura la capacité d’inventer des mots, de recréer des conjugaisons pour des verbes qu’il n’a jamais rencontrés, etc.
Une fois les unités d’analyse découpées, nous aurons aussi besoin d’une méthode pour les traduire et les entrer dans notre modèle. La façon la plus simple est le one-hot encoding. Comme pour notre variable catégorique plus haut concernant les types de couvert, ici chaque mot (ou caractère) possédera sa propre variable/colonne dans la matrice de données, qui contiendra un 1 pour les fois où l’unité d’encodage correspond à ce mot, et un 0 pour toutes les fois où ce ne l’est pas. Bien que techniquement très simple, il faut réaliser que notre matrice contiendra BEAUCOUP de 0. On parle en langage mathématique de matrices creuses (sparse matrix). Ces matrices occupent beaucoup d’espace mémoire pour le peu d’information qu’elles contiennent.
C’est pourquoi on utilise souvent en apprentissage profond le plongement lexical (word embedding). On peut penser au plongement lexical comme l’équivalent d’une ACP pour des séquences de texte. L’idée est que, plutôt que d’avoir une matrice de dimensions gigantesques (par exemple un vocabulaire de 30 000 mots aura besoin de 30 000 dimensions pour travailler…), le plongement produira un espace réduit, souvent à 256 ou 1024 dimensions. Chaque mot possédera une coordonnée dans chacune des dimensions, ce qui formera un espace multidimensionnel de représentation du vocabulaire. Plutôt que d’être généré statiquement, cet espace de coordonnées sera aussi entraîné avec le modèle, ce qui permettra par exemple à des synonymes de se trouver très près les uns des autres. Certains axes pourraient aussi représenter certaines constructions du langage, comme un axe masculin-féminin, un axe vivant-non-vivant, etc. Les plongements peuvent aussi être réutilisés d’un projet à l’autre, permettant d’accélérer grandement la période d’entraînement du modèle.
Exemple d’analyse de sentiment avec IMDB
Voyons maintenant un premier exemple d’apprentissage profond avec du texte. Nous travaillerons pour cet exemple avec un jeu de données classique contenant des critiques de films tirées du site IMDB, où chaque critique est associée à un variable binaire, dont la valeur représente le fait que la critique ait été positive ou négative.
Si vous allez explorer le dossier de critiques, vous verrez que chaque critique possède son propre fichier .txt, et que les critiques sont organisées en deux dossiers, pos et neg selon que la critique était positive ou négative.
Nous chargerons donc d’abord ces données dans un grand tableau de données, contenant une colonne avec la critique et une autre colonne avec le résultat :
dossier <- "data/aclImdb/train/"
fichiers <- list.files(dossier,recursive = TRUE,full.names = TRUE)
reviews <- map_df(
fichiers,
~list(
label = rev(str_split_1(.,"/"))[2],
text = readChar(.,100000)
)
)
Deux choses à noter concernant ce code. Tout d’abord, j’utilise la fonction str_split1 pour découper chacun des morceaux du chemin du fichier, qui ressemblera par exemple à “~/Desktop/data/aclImdb/train/pos/0_3.txt”. ensuite, j’inverse ce petit vecteur et je prend le 2e morceau, qui correspondra à la partie “pos” ou “neg” du chemin.
Ensuite, pour récupérer le contenu de la critique comme tel, je ne peux pas utiliser le classique read.csv ou read.table, puisque l’information n’est pas structurée. Je dois donc utiliser la fonction readChar. Cette dernière doit absolument recevoir un nombre de caractères à charger. J’ai mis 100 000 comme nombre arbitrairement grand, pour m’assurer d’attraper tout le contenu de toutes les critiques.
Une fois le contenu récupéré, on peut le découper en unités d’analyse. Plutôt que de faire ce travail manuellement, je vous conseille fortement d’utiliser les fonction de Keras prévues à cet effet. La stratégie est alors la suivante : préparer un objet tokenizer, et l’entraîner sur notre jeu de données. Dans un deuxième temps, on utilise cet objet tokenizer pour transformer notre jeu de données en unités d’analyse. Remarquez que pour ne pas surcharger notre modèle, nous ne considérerons que les 10 000 mots les plus communs à travers nos critiques :
max_features <- 10000
tokenizer <- text_tokenizer(num_words = max_features) %>%
fit_text_tokenizer(reviews$text)
sequences <- texts_to_sequences(tokenizer, reviews$text)
Ensuite, pour comme la première couche de notre modèle doit toujours obtenir des entrées de mêmes dimensions, on coupe chacun des critiques à ses 35 premiers mots (parmi les 10 000 mots les plus fréquents). Cette fonction étirera aussi les critiques plus courtes à 35 mots. Si nous n’étions pas dans une démonstration, nous aurions évidemment plus utiliser plus de mots, pour de meilleurs résultats, mais aussi un modèle plus long à ajuster.
max_len <- 35
sequences <- pad_sequences(sequences,max_len)
Une fois cette préparation effectuée, on peut préparer notre modèle comme tel. Ce dernier comprendra 3 couches : une couche de plongement lexical, une couche pour transformer la sortie du plongement multidimensionnel en une sortie unidimensionnelle et finalement une couche densément connectée pour effectuer la classification comme tel entre positif et négatif :
model <-
keras_model_sequential() %>%
layer_embedding(input_dim = max_features, output_dim = 8, input_length = max_len) %>%
layer_flatten() %>%
layer_dense(units = 1, activation = "sigmoid")
On peut ensuite compiler ce modèle :
model %>% compile(
optimizer = "rmsprop",
loss = "binary_crossentropy",
metrics = c("acc")
)
Et le lancer pour 10 époques. Remarquez qu’à cette étape, il faut convertir les étiquettes pos/neg en 1 et en 0 pour que le modèle puisse les utiliser.
history <- model %>% fit(
sequences,
ifelse(reviews$label=="pos",1,0),
epochs = 10,
batch_size = 32,
validation_split = 0.2,
verbose = 0
)
history
Final epoch (plot to see history):
loss: 0.2348
acc: 0.9073
val_loss: 0.7099
val_acc: 0.6995
plot(history)
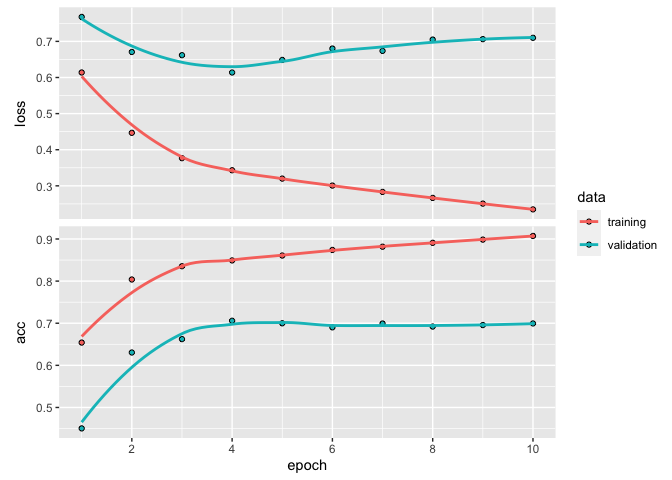
Donc, pas trop mal pour un premier essai avec 69% de succès, considérant que l’on ne traite que les 35 premiers mots de la critique. Et surtout, notre modèle n’accorde aucune importance à l’ordre des mots ou à leur organisation. Il ne fait que regarder si un mot est présent ou non. Nous verrons dans la prochaine section comment faire quelque chose de plus naturel.
Les réseaux neuroneaux récurrents
Notre cerveau, lorsque l’on analyse un texte, va beaucoup plus loin que simplement regarder la présence/absence de certains mots dans le texte. On avance de gauche à droite dans notre lecture. Chaque nouveau mot ajoute de l’information supplémentaire à ce que l’on avait déjà lu. On contextualise l’information.
Il existe en apprentissage profond certains types de couches effectuant exactement cette tâche : les couches récurrentes (recurrent neural networks, RNN). Ces dernières fonctionnent un peu comme des boucles for en programmation. Elles traitent de façon séquentielle chaque élément reçu en entrée. La première étape part d’un état vide, et traite le premier élément de la séquence. Au moment de traiter la deuxième entrée, celle-ci est combinée non pas à un état vide, mais aux sorties de la première étape. Au moment de la troisième entrée, celle-ci est traitée avec les sorties de la deuxième, etc.
Bien que leur fonctionnement soit plutôt intuitif, les couches RNN ne sont pas très utilisées dans la réalité, à cause de ce que les experts ont nommé le problème du gradient qui disparaît (vanishing gradient problem). Bien que théoriquement l’information pourrait survivre d’une itération à l’autre de la boucle, dans la réalité, l’information n’est pas stockée à long terme dans le RNN. Un peu comme si sa mémoire de travail était trop courte pour considérer toute l’information.
C’est pour cette raison que dans la plupart des cas, on utilise plutôt des couches de type LSTM (Long Short-Term Memory). Ces dernières incluent ce qu’on pourrait se représenter comme un convoyeur d’information, qui permet de retenir certaines informations éventuellement utiles des itérations précédentes pour les présenter aux itérations suivantes, même si cette information n’est pas imbriquée directement dans les sorties de l’itération.
Nous utiliserons ce type de couche LSTM dans notre dernier modèle pour l’atelier, un générateur de texte style ChatGPT
Un générateur de texte style ChatGPT
Avec tout ce que l’on a vu jusqu’à présent, on a maintenant tous les morceaux nécessaires pour se créer un mini-ChatGPT, capable de générer du texte pour nous.
Les principes que nous verrons sont plus ou moins les mêmes qui sous-tendent le fonctionnement des modèles comme ChatGPT ou Google Bard, mais nous devrons fonctionner à des échelles beaucoup plus réduites. Une des clés de ChatGPT est qu’il a pu être entraîné avec 570 Gb de texte provenant de Wikipedia, de livres et l’internet en général, soit 300 milliards de mots.
Notre tentative sera plus modeste. Nous nous ferons plutôt une mini-JK Rolling, entraînée uniquement sur le texte de Harry Potter à l’école des sorciers. Pour des raisons légales, je ne peux pas distribuer ici le texte intégral du livre, mais quelques minutes sur Google devraient vous permettre de le trouver facilement en format texte.
La première étape sera, évidemment, de charger le texte entier du livre :
chemin <- "data/Harry Potter and the Sorcerer's Stone.txt"
texte <- tolower(readChar(
chemin,
file.info(chemin)$size
))
nchar(texte)
[1] 437562
Remarquez que j’en profite pour tout de suite convertir tout le texte en minuscules, ce qui simplifiera le travail d’encodage et d’analyse par le modèle. Au total, nous travaillerons avec un peu moins d’un demi million de caractères, soit environ 75 000 mots.
La stratégie pour entraîner notre modèle sera de découper le texte en séquences de caractères, puis de l’entraîner à prédire le caractère suivant. Et c’est exactement ce que fait ChatGPT. Ce n’est ni plus ni moins qu’une machine à prédire le prochain mot.
Pour maximiser nos données, il est tout à fait normal que nos séquences se chevauchent. Les documents consultés utilisaient souvent un pas de 3 caractères. Ici, pour limiter la quantité de mémoire nécessaire et accélérer nos calculs pendant l’atelier, j’étirerai le pas à 10 caractères :
longueur_sequences <- 50
espacement_sequences <- 10
debuts_sequences <- seq(1,nchar(texte) - longueur_sequences, by = espacement_sequences)
sequences <- str_sub(texte,debuts_sequences,debuts_sequences+longueur_sequences-1)
cibles <- str_sub(texte, debuts_sequences + longueur_sequences, debuts_sequences + longueur_sequences)
Donc, l’idée ici est qu’avec str_sub, on extrait toutes les séquences de caractères du livre, et on va ensuite extraire nos cibles, soit le caractère suivant chacune des séquences.
Voici, à titre d’illustration, nos 2 premières séquences et les cibles associées :
sequences[1]
[1] "harry potter and the sorcerer's stone\nchapter one\n"
cibles[1]
[1] "t"
sequences[2]
[1] "er and the sorcerer's stone\nchapter one\nthe boy wh"
cibles[2]
[1] "o"
Si on voulait travailler proprement, il faudrait éliminer les sauts de lignes (\n) avant de traiter les séquences, mais nous n’avons que 1,5 heures pour faire cet atelier!
L’étape suivante consistera à découper nos unités d’analyse avec un tokenizer. Contrairement à l’exemple précédent, nous travaillerons au niveau des caractères plutôt qu’au niveau des mots :
tokenizer <- text_tokenizer(char_level = TRUE, filters = "") %>%
fit_text_tokenizer(sequences)
nb_classes <- length(tokenizer$word_index)+1
x <- texts_to_sequences(tokenizer, sequences) %>% to_categorical()
y <- texts_to_matrix(tokenizer, cibles, mode = "binary")
Remarquez qu’il faut ajouter 1 au dictionnaire du tokenizer pour obtenir le vrai nombre de classes, puisque l’index sous-jacent en Python commence à 1 alors qu’il devrait normalement commencer à zéro. C’est un détail technique agaçant, mais qu’il ne faut pas oublier de faire pour les étapes suivantes.
J’en profite dans la même étape pour transformer les données immédiatement au format one-hot encoded.
Notre modèle, pour l’exemple, sera extrêmement simple, soit une seule couche LSTM et une couche densément connectée qui servira à prédire le prochain caractère :
model <- keras_model_sequential() %>%
layer_lstm(units = 128,input_shape = c(longueur_sequences, nb_classes)) %>%
layer_dense(units = nb_classes, activation = "softmax")
model %>%
compile(
loss = "categorical_crossentropy",
optimizer = optimizer_rmsprop(learning_rate = 0.01)
)
Pour que le que modèle prenne un temps raisonnable à rouler pour l’atelier, nous ne l’entraînerons que sur 10 époques, mais le vrai modèle en nécessitera probablement près d’une centaine. Malgré tous les raccourcis utilisés, le modèle prendra tout de même quelques minutes à s’entraîner…
history <- model %>% fit(
x, y, batch_size = 128, epochs = 10,
verbose = 0
)
history
Final epoch (plot to see history):
loss: 1.195
plot(history)
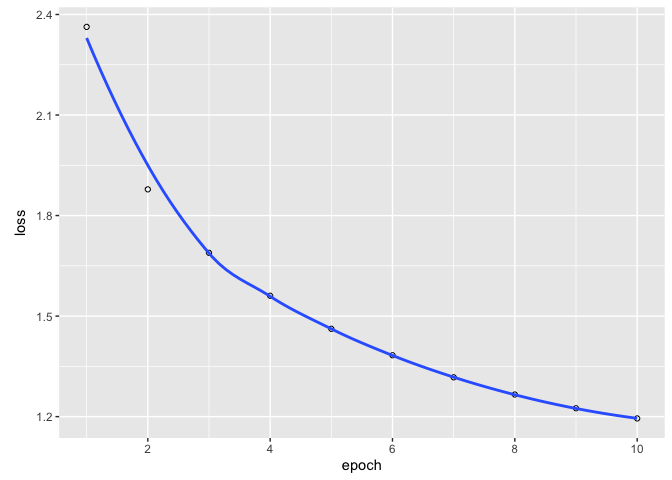
Utiliser notre générateur de texte!
Juste avant de générer du texte, il est important de comprendre que notre modèle ne prédit pas le prochain caractère comme tel. Il nous sort en fait une matrice avec la probabilité que chaque caractère soit le prochain. Nous avons donc besoin d’une fonction qui utilisera cette matrice de probabilités pour effectivement choisir la prochaine lettre ou le prochain caractère.
Une façon simple de faire serait de toujours choisir le caractère ayant la probabilité la plus forte d’être le suivant. Cette approche génère cependant des résultats répétitifs et peu intéressants.
Une façon plus intéressante serait de créer un générateur stochastique. Ce dernier utilise la matrice de probabilités fournie par le modèle pour piger le prochain caractère. Plus la probabilité que ce caractère soit le prochain est forte, plus les chances que ce dernier soit effectivement choisit sont élevées.
La difficulté avec cette approche est de calibrer la “quantité de hasard” nécessaire. Une approche qui pigerait entièrement aléatoirement serait aussi inutile qu’une approche qui choisit toujours le caractère le plus probable.
Les experts dans le domaine ont donc proposé une petit calcul pour transformer la matrice de probabilité selon un paramètre qu’ils ont nommé la température. Plus le paramètre de température est élevé, plus le générateur est aléatoire (i.e. surprenant et créatif). Plus la température est faible, plus il sera prévisible. Ce chiffre doit être calibré pour chaque application.
Voici donc la fonction qui effectue ce petit calcul :
choisir_prochain_caractere <- function(preds, temperature = 1.0) {
preds <- as.numeric(preds)
preds <- log(preds) / temperature
exp_preds <- exp(preds)
preds <- exp_preds / sum(exp_preds)
which.max(t(rmultinom(1, 1, preds)))
}
Pour démarrer notre générateur de texte, nous avons aussi besoin d’une amorce, un début de phrase. ChatGTP est entraîné pour répondre à des questions, mais dans notre cas, on fournira un début de paragraphe, et on laissera notre modèle écrire la suite.
Pour que cela fonctionne bien, notre amorce doit avoir le même nombre de caractères que nos séquences d’entraînement, quitte à remplir avec du vide à gauche de notre phrase :
nouveau_texte <- str_pad("harry stopped. it ", side = "left", width = longueur_sequences)
Maintenant, il ne nous reste qu’à faire autant de fois que nécessaire la boucle suivante :
- Prendre la séquence des 50 derniers caractères de notre paragraphe
- Préparer une matrice de prédictions du prochain caractère pour cette séquence
- Utiliser la fonction qui pige dans la matrice un caractère en fonction de la température
- Convertir cette prédiction en texte
- L’ajouter à notre paragraphe
Voici à quoi cela pourrait ressembler :
for (i in 1:200) {
# Construire une séquence pour nourrir l'algorithme à partir de ce qui
# a déjà été prédit (au début : rien, juste ce que nous on a préparé)
sequence_pour_prediction <-
texts_to_sequences(
tokenizer,
str_sub(nouveau_texte,-longueur_sequences)
) %>%
to_categorical(num_classes = nb_classes)
# Obtenir la matrice de prédictions
predictions_matrix <- model %>% predict(sequence_pour_prediction, verbose = 0)
# Convertir la prédiction en caractère
nouveau_caractere <- tokenizer$sequences_to_texts(
list(list(choisir_prochain_caractere(predictions_matrix)-1))
)
# Coller le caractère au texte généré
nouveau_texte <- paste0(nouveau_texte,nouveau_caractere)
}
print(nouveau_texte)
[1] " harry stopped. it was as they companted \"it?\"\n\"it's sdadzed sfoltsled, on the encd louking as harry, potters. you she tablevone spolled\nof jurr find nearer-had and the dran take awhell point.\n\"why,\" somethious rone to "
Évidemment, avec seulement 10 générations et si peu de séquences, ce n’est rien d’impressionnant, mais si vous êtes le moindrement patientes, essayez avec 50 ou 100 générations, remettez le pas entre les séquences à 3 plutôt que 10 et expérimentez avec des températures variant entre 0.5 et 1.5. Vous devriez obtenir de bons résultats!
Par exemple, avec 120 générations, un pas de 3 et une température de 0.1, on arrive à ceci :
harry stopped. dumbledore from the station. he cluhbed him a thing off after the door.\nthe un’ver silver of the ground was the syiol in a wizard work out of the train the train to the foot of the mais. neville knew whoce of them silver the starts and then he was started students were all the doorway. he could be the stone around the corner with the wall. harry said toward a large bane and the potions were all the team any
On est clairement pas encore au niveau de ChatGPT, mais c’est déjà une nette progression par rapport à la sortie précédente. On reconnaît des phrases presque lisibles en plusieurs endroits.
Notez qu’avec autant de générations, vous devrez probablement aussi réduire le taux d’apprentissage (learning rate), sans quoi votre modèle risque de parfois faire de grands sauts loin de la solution optimale…
Conclusion
Vous voyez donc qu’il n’y a rien de “magique” dans les grands modèles de langage comme ChatGPT ou Google Bard. Les principes sont connus depuis au moins 2018, mais il a fallu plusieurs années avant qu’une compagnie investisse beaucoup de dollars dans l’infrastructure et le temps nécessaire à entraîner de tels modèles sur des quantités immenses de données. Il n’y a pas de compréhension ou de conscience, pas de concept de vérité ou de mensonge. Juste un modèle statistique qui tente très fort de prédire qu’elle aurait été le prochain caractère pour continuer la séquence.
Pour se donner une idée des différences d’échelle, le modèle que nous venons d’entraîner comprend environ 100 000 paramètres.
summary(model)
Model: "sequential_3"
________________________________________________________________________________
Layer (type) Output Shape Param #
================================================================================
lstm (LSTM) (None, 128) 93184
dense_7 (Dense) (None, 53) 6837
================================================================================
Total params: 100021 (390.71 KB)
Trainable params: 100021 (390.71 KB)
Non-trainable params: 0 (0.00 Byte)
________________________________________________________________________________
GPT-3, la version gratuite de ChatGPT comprend 175 milliards de paramètres et la version la plus récente, GPT-4, en comprendrait plus de mille milliards (trillion) selon plusieurs sources.
Une des limitations de ces modèles est justement la puissance informatique nécessaire à les rouler et les coûts associés. À l’heure actuelle, aucune de ces compagnies d’IA n’a réussi à rentabiliser leurs modèles.
Références
La majorité de cet atelier a été adaptée du livre Deep Learning with R (2018) de l’auteur de Keras François Chollet et du fondateur de RStudio J.J. Allaire. Il s’agira clairement de votre meilleur point de départ dans le monde de l’apprentissage profond avec R.
Comme toujours, RStudio a un excellent aide-mémoire concernant la librairie Keras (https://github.com/rstudio/cheatsheets/raw/master/keras.pdf) qui résume tous les types de couches existantes, ainsi que plusieurs opérations que nous n’avons pas touchées ici, incluant comment sauvegarder et recharger un modèle.