Environnements Python avec Conda
Installation, utilisation et intégration dans VSCode
Thierry Laurent St-Pierre
Mars 2026
Dépôt GitHub : tofunori/numerilab-vscode-conda
Table des matières
Formation
- Présentation
- 1. Introduction
- 2.1 Théorie Conda
- 2.2 Installation Conda
- 2.3 Environnements Conda
- 2.4 Librairies géospatiales
- 2.5 Commandes essentielles
- 3.1 Interface VSCode
- 3.2 Extensions VSCode
- 3.3 Terminal et Conda
- 3.4 Git et GitHub
- 3.5 Démarche complète
- 4. Ressources
Annexes
- Annexe A — Test de l’environnement
- Annexe B — Importation satellite
- Annexe C — Extensions VSCode recommandées
- Annexe D — Configuration VSCode
Présentation
Aperçu
Cette formation vous guide à travers la configuration complète d’un environnement de développement professionnel pour la géomatique.
Durée estimée
- Théorie : 60 mins
- Exemples pratiques : 30 mins
- Total : 90 mins
Pré-requis
- Aucune connaissance préalable
- Windows 10+, macOS, ou Linux
- ~2 GB d’espace disque
Résultats attendus
À la fin de cette formation, vous saurez :
★ Installer et configurer Conda (Miniforge)
★ Créer et gérer des environnements isolés
★ Installer des librairies géospatiales complexes
★ Configurer VSCode pour la géomatique et l’analyse spatiale
★ Utiliser Git et GitHub
★ Rendre vos projets reproductibles et partageable
Structure
La formation est organisée en 4 sections :
- Introduction - Contexte et motivation
- Conda - Gestion des environnements Python
- VSCode - Éditeur intégré pour géomatique
- Ressources - Fichiers et références
Points clés
♦︎ Conda permet :
- ✓ Installation fiable de GDAL, GeoPandas, Rasterio
- ✓ Isolation des environnements par projet
- ✓ Reproductibilité garantie via
environment.yml
♦︎ VSCode offre :
- ✓ Intégration native Conda
- ✓ Terminal intégré
- ✓ Extensions puissantes pour géomatique
- ✓ Support Jupyter natif
♦︎ Git + GitHub assurent :
- ✓ Traçabilité des changements
- ✓ Sauvegarde cloud
- ✓ Collaboration efficace
1. Introduction
Vue d’ensemble rapide
Contexte
Vous travaillez sur un projet avec des données géospatiales et avez besoin de :
- ✓ Installer des librairies complexes (GDAL, GeoPandas, Rasterio)
- ✓ Maintenir plusieurs projets avec des dépendances différentes
- ✓ Collaborer avec d’autres chercheurs
- ✓ Documenter et reproduire vos analyses
♦︎ Pourquoi Conda ?
⚠︎ Python natif ne gère pas bien les dépendances C comme GDAL et PROJ. Conda résout ce problème en téléchargeant des versions pré-compilées.
♦︎ Pourquoi VSCode ?
- ✓ Léger et gratuit
- ✓ Extensions puissantes pour géomatique
- ✓ Terminal intégré détecte Conda automatiquement
- ✓ Git intégré
- ✓ Support Jupyter natif
♦︎ Pourquoi Git/GitHub ?
- ✓ Traçabilité des modifications apportées
- ✓ Collaboration facile entre personnes
- ✓ Reproductibilité garantie
- ✓ Sauvegarde sur cloud via GitHub
2.1 Théorie Conda
Le problème que Conda résout
Vous avez probablement rencontré cette situation frustante : vous installez pip install gdal pour un projet de géomatique, et vous recevez une erreur du type :
ERROR: Could not find a version that satisfies the requirement GDAL
ERROR: Could not build wheels for GDAL
Ou pire, l’installation réussit, mais GDAL ne trouve pas la bibliothèque PROJ au moment de l’exécution. Pourquoi ? Parce que GDAL n’est pas qu’une librairie Python. C’est une collection de outils géospatiaux écrits en C/C++ (GDAL, GEOS, PROJ, TIFF, etc.) qui ont besoin d’être compilées correctement et de fonctionner ensemble.
Python seul (avec pip) ne peut pas gérer ces dépendances C. C’est le rôle de Conda.
Note technique : pip peut installer facilement certaines bibliothèques (PyTorch, seaborn) car elles fournissent des wheels (.whl) — des librairies Python pré-compilées sur PyPI. GDAL et Rasterio ne fournissent PAS de wheels pour Windows, forçant pip à compiler depuis le code source, ce qui échoue fréquemment.
Qu’est-ce que Conda ?
Conda est un gestionnaire de paquets et d’environnements qui :
- Télécharge des versions pré-compilées de GDAL, PROJ, et autres (au lieu de compiler localement)
- Garantit que toutes les dépendances C sont compatibles entre elles
- Permet de créer des environnements isolés pour chaque projet
Anaconda vs Miniforge : Quel choisir ?
Avant de choisir votre gestionnaire, il faut comprendre qu’Anaconda et Miniforge sont deux distributions de Conda (il en existe d’autres : Miniconda, Mambaforge, etc.).
Anaconda est la distribution “complète” : elle installe ~250 librairies pré-compilées (NumPy, Pandas, Matplotlib, etc.) d’emblée. C’est comme recevoir un couteau suisse avec 40 outils alors que vous n’en utiliserez que 3.
Miniforge est la distribution “minimale” : elle installe seulement Conda et vous laisse installer ce dont vous avez besoin. Plus léger, plus rapide, et plus flexible.
| Aspect | Anaconda | Miniforge |
|---|---|---|
| Taille installation | ~3 GB | ~150 MB |
| Librairies pré-installées | ~250 (NumPy, Pandas, etc.) | Aucune |
| Temps installation | ~10-15 minutes | ~2-3 minutes |
| Licence | Commerciale (payante pour pro) | Open Source (100% libre) |
| Canal par défaut | defaults (Anaconda Inc.) |
conda-forge (communautaire) |
| Idéal pour | Débutants absolus | Projets professionnels/géomatique |
★ Ma recommandation pour ce cours : Miniforge avec le canal conda-forge
Pourquoi ? Parce que pour la géomatique et l’analyse de données spatiales, vous avez besoin de versions récentes et stables de GDAL, PROJ, et GeoPandas. Miniforge + conda-forge garantit des mises à jour régulières et une meilleure compatibilité avec l’écosystème géospatial.
Le rôle crucial de conda-forge
Conda utilise des canaux (channels) pour télécharger les librairies. Pensez à un canal comme une source/dépôt de librairies.
Canal defaults (fourni par Anaconda Inc.)
- Librairies maintenues par l’équipe Anaconda
- Mise à jour lente (focus sécurité)
- Problème : GDAL et géospatial souvent obsolètes
Canal conda-forge (maintenu par la communauté)
- ~20,000 librairies maintenues par des scientifiques et développeurs
- Mise à jour rapide (nouvelles versions de GDAL disponibles rapidement)
- Idéal pour géomatique et science des données
- 100% gratuit et transparent (toutes les versions disponible sur GitHub)
☞ Pour explorer : Consultez le dépôt conda-forge sur GitHub pour voir les milliers de librairies disponibles.
Exemple concret :
conda install gdal # [OK] Fonctionne (utilise conda-forge)
conda install -c conda-forge gdal # [OK] Fonctionne aussi (explicite)
conda install gdal # [!] Version obsolète du canal defaults
conda install -c conda-forge gdal # [OK] Version à jour de conda-forge
Alternatives à Conda : Quand les utiliser ?
Vous avez d’autres outils pour gérer les librairies Python. Voici comment les utiliser :
| Outil | Utilité | Quand l’utiliser | Limitation |
|---|---|---|---|
| Conda | Gestion complète (Python + dépendances C) | Toujours pour géomatique | - |
| Pip | Installer librairies Python uniquement | Librairies simples (seaborn, pandas) | Ne compile pas dépendances C |
| Mamba | Remplaçant ultra-rapide de Conda | Conda trop lent ? Installez mamba | Encore jeune (moins stable) |
| uv | Alternative moderne à pip | Projets Python pur (sans dépendances C) | Récent, communauté petite |
| VENV | Environnements Python seulement | Jamais pour géomatique | Pas de dépendances C |
Bon à savoir : Miniforge fournit déjà mamba aux côtés de conda, vous pouvez donc immédiatement profiter de son solveur plus rapide.
Notre choix pour ce cours : Conda (et mamba quand vous voulez accélérer les installations).
Pourquoi isoler les environnements ?
Vous avez plusieurs projets de recherche sur lesquels vous travaillez ? Chacun a probablement besoin de versions différentes des mêmes librairies.
Scénario réaliste :
- Projet A : Cartographie de zones protégées (GeoPandas 0.12, GDAL 3.6)
- Projet B : Classification d’images satellites avec Random Forest (GeoPandas 0.14, GDAL 3.8, scikit-learn, rasterio)
Naïvement, vous pourriez installer toutes les librairies globalement. Mais quand vous installez GeoPandas 0.14 pour le Projet B, cela casse les dépendances du Projet A (qui attend 0.12).
♦︎ Avec Conda, chaque projet a son propre “environnement virtuel” avec ses propres versions :
conda activate projet-a # Vous utilisez GeoPandas 0.12
conda activate projet-b # Vous utilisez GeoPandas 0.14
conda deactivate # Revenir à l'environnement base
Avantage : Zéro conflit, zéro casse-tête. Chaque projet vit dans son propre “appartement virtuel”.
2.2 Installation Conda
♦︎ Étape 1 : Télécharger Miniforge
- Visiter github.com/conda-forge/miniforge
- Télécharger l’installeur Windows :
Miniforge3-Windows-x86_64.exe
♦︎ Étape 2 : Installer
- Double-cliquer l’exécutable
- Accepter la licence
- Laisser chemin par défaut (ex:
C:\Users\YourName\miniforge3) - IMPORTANT ⚠︎ : Cocher “Register Miniforge3 as my default Python”
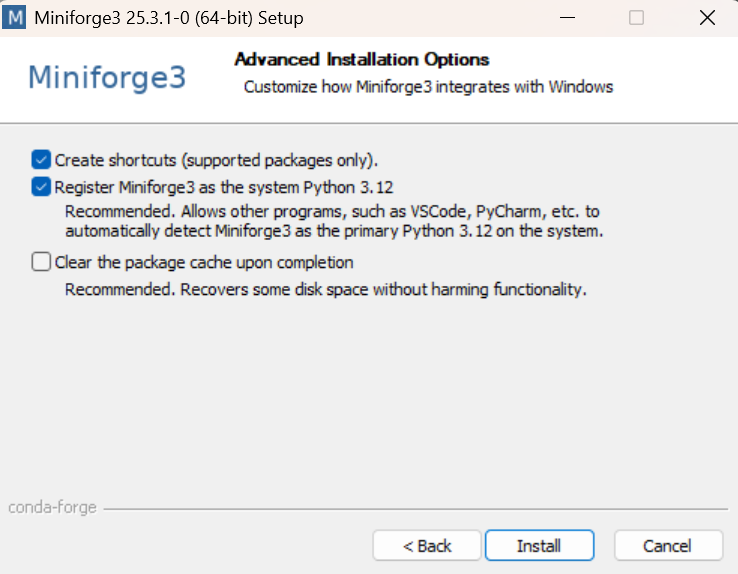
Figure 1 : Options d’installation - Cochez “Register Miniforge3 as the system Python 3.12” pour permettre à VSCode et autres programmes de détecter automatiquement Miniforge
macOS/Linux :
bash Miniforge3-MacOSX-x86_64.sh
source ~/miniforge3/bin/activate
♦︎ Étape 3 : Vérifier l’installation
Ouvrir Command Prompt (Windows) ou Terminal (macOS/Linux) et taper :
conda --version
✓ Résultat attendu :
conda 25.x.x
♦︎ Étape 4 : Initialiser Conda
Méthode recommandée : Miniforge Prompt
Le Miniforge Prompt est un terminal pré-configuré installé avec Miniforge qui active automatiquement Conda.
- Appuyez sur la touche Windows
- Tapez “Miniforge Prompt”
- Lancez l’application
✓ Résultat attendu :
(base) C:\Users\VotreNom>
Le préfixe (base) indique que l’environnement Conda de base est activé.
Méthode alternative : Intégration PowerShell (optionnel)
Si vous préférez utiliser PowerShell standard au lieu de Miniforge Prompt :
conda init powershell
Fermez et rouvrez PowerShell. Vous devriez voir (base) apparaître dans votre prompt.
⚠︎ Si (base) n’apparaît pas, vérifiez que conda init a modifié votre profil :
cat $PROFILE | Select-String "conda"
Si aucune ligne contenant “conda” n’apparaît, conda init n’a pas fonctionné correctement.
☞ Solution : Utilisez plutôt Miniforge Prompt (méthode recommandée ci-dessus).
Note : VSCode détecte automatiquement Conda, peu importe la méthode choisie.
2.3 Environnements Conda
Créer un nouvel environnement
conda create -n geo-env python=3.11
Explication :
conda create: créer un environnement-n geo-env: nom de l’environnementpython=3.11: version Python spécifiée
Activer l’environnement
conda activate geo-env
conda activate geo-env
Vous verrez (geo-env) au début de votre invite de commande.
Désactiver l’environnement
conda deactivate
Vous reveniez à l’environnement (base).
Lister vos environnements
conda env list
Résultat :
#
base * C:\Users\YourName\miniforge3
geo-env C:\Users\YourName\miniforge3\envs\geo-env
Figure 2 : Démonstration des commandes conda - Installation des librairies avec mamba, inspection avec conda list, et activation d’environnement. L’astérisque () indique l’environnement actif.*
2.4 Librairies géospatiales
Pourquoi certaines librairies plutôt que d’autres ?
Maintenant que vous avez un environnement Conda isolé, vous devez l’équiper des outils appropriés pour la géomatique. Mais quelles librairies choisir parmi les ~20,000 disponibles sur conda-forge ?
La réponse dépend de vos besoins selon le projet. En géomatique, vous travaillez généralement avec deux types de données :
Données vectorielles (points, lignes, polygones) - Exemple : limites administratives, routes, bâtiments - Librairie clé : GeoPandas
Données raster (grilles de pixels, images satellites) - Exemple : images Sentinel-2, modèles d’élévation, cartes climatiques - Librairies clés : GDAL, Rasterio
Pour les visualiser et explorer vos résultats, vous avez aussi besoin de librairies de science des données (NumPy, Pandas, Matplotlib) et d’outils pour la cartographie interactive (Jupyter, Folium, Leafmap, Anymap).
Installation des librairies géospatiales complètes
Activez votre environnement et installez toutes les librairies d’un seul coup :
conda activate geo-env
conda install -c conda-forge \
geopandas \
gdal \
rasterio \
folium \
jupyter \
jupyterlab \
matplotlib \
numpy \
pandas \
scipy
Note importante : Si vous utilisez Miniforge (recommandé dans ce cours), le -c conda-forge est optionnel car conda-forge est déjà le canal par défaut. Vous pouvez donc écrire simplement conda install geopandas gdal rasterio ....
Note performance : conda prendra ~2-5 minutes pour résoudre les dépendances et compiler. C’est normal (voir 2.1 pour comprendre pourquoi). Utilisez mamba si vous êtes impatient comme moi ☺︎:
mamba install geopandas gdal rasterio folium jupyter jupyterlab matplotlib numpy pandas scipy
Librairies clés expliquées en détail
| Librairie | Catégorie | Utilité | Exemple d’usage |
|---|---|---|---|
| GeoPandas | Données spatiales | DataFrames avec géométries spatiales (points, lignes, polygones). Interface Python pour données vectorielles. | Charger une shapefile de zones protégées, calculer surfaces, fusionner polygones |
| GDAL/OGR | Drivers géospatials | Lecture/écriture de formats raster et vecteur. Transformations de projections. Sous-jacent à GeoPandas et Rasterio. | Convertir GeoTIFF en NetCDF, reprojeter en WGS84 |
| Rasterio | Données raster | Interface moderne et pythonique pour manipuler données raster. Plus simple que GDAL direct. | Lire bandes d’une image satellite Sentinel-2, calculer NDVI |
| Folium | Cartographie web | Créer des cartes interactives Leaflet (OpenStreetMap). Parfait pour explorer données sur le web. | Afficher couches vectorielles sur carte zoomable, créer heatmaps |
| NumPy | Calcul numérique | Opérations vectorisées sur tableaux. Base de presque tous les calculs géospatiaux. | Calculer statistiques raster, algèbre cartographique |
| Pandas | Data science | DataFrames pour données tabulaires. Indispensable pour analyses statistiques. | Nettoyer attributs vectoriels, grouper par région |
| Matplotlib | Visualisation | Graphiques 2D statiques. Parfait pour publications scientifiques. | Tracer histogrammes NDVI, graphes en barres d’analyse |
| Jupyter | Notebooks interactifs | Environnement interactif pour explorer données et documenter analyses. Mix code, texte, graphiques. | Cahier d’analyse Sentinel-2 partageables |
| SciPy | Calcul scientifique | Algorithmes numériques avancés (optimisation, statistiques, filtrage). | Appliquer filtres spatiaux, analyses statistiques géospatialisées |
Note sur PROJ (dépendance critique)
PROJ est une librairie fondamentale pour gérer les systèmes de coordonnées (CRS) et les transformations entre projections cartographiques. Elle est installée automatiquement comme dépendance de GDAL, Rasterio et GeoPandas. Si vous rencontrez des erreurs mentionnant « PROJ » ou « CRS » (Coordinate Reference System), c’est généralement lié aux projections de vos données géospatiales. Vous n’avez pas besoin de l’installer séparément, mais il est important de comprendre son rôle dans la gestion des coordonnées.
Vérifier l’installation
Après l’installation, testez que toutes les librairies sont accessibles :
python -c "import geopandas; print(f'GeoPandas {geopandas.__version__}')"
python -c "import rasterio; print(f'Rasterio {rasterio.__version__}')"
python -c "from osgeo import gdal; print(f'GDAL {gdal.__version__}')"
Vous devriez voir des numéros de version (ex: GeoPandas 0.14.0). Si vous recevez ModuleNotFoundError, relancez le terminal ou vérifiez que vous avez bien activé geo-env.
Validation complète : Pour tester votre environnement, consultez le notebook 01a-validation-rapide.ipynb (section 3.3 pour l’exécution).
Environnements reproductibles avec environment.yml
Le problème : Vous finissez votre projet en mai 2025 avec GDAL 3.8.0. Votre collègue clone votre code en décembre 2025, installe les librairies en novembre 2025 (versions plus récentes), et soudain votre code ne fonctionne plus. Conflit de versions!
La solution : Exportez votre environnement exact dans un fichier environment.yml qui “gèle” les versions :
conda env export > environment.yml
Note importante : Le fichier
environment.ymlsera créé dans le répertoire courant de votre terminal. Assurez-vous d’être à la racine de votre projet avant d’exécuter cette commande. Vérifiez votre emplacement avecpwd(PowerShell) oucd(Windows).
Contenu du fichier généré :
name: geo-env
channels:
- conda-forge
- defaults
dependencies:
- python=3.11
- geopandas=0.14.0
- gdal=3.8.0
- rasterio=1.3.0
- folium=0.14.0
- jupyter=1.0.0
- jupyterlab=4.0.0
- matplotlib=3.8.0
- numpy=1.24.0
- pandas=2.1.0
- scipy=1.11.0
- pip
- ca-certificates
- certifi
- ... (autres dépendances C et de base)
Ce fichier agit comme une “recette” : n’importe qui peut recréer EXACTEMENT votre environnement :
conda env create -f environment.yml
Important : Committez ce fichier environment.yml dans votre repo Github (nous verrons ça en section 3.4). C’est l’une des meilleures pratiques de reproductibilité en science.
Bonus : Créer environnement avec versions spécifiques
Si vous avez besoin d’une version particulière de GDAL (pour compatibilité), vous pouvez être explicite dès la création :
conda create -n geo-env \
python=3.11 \
geopandas=0.14.0 \
gdal=3.8.0 \
rasterio=1.3.0 \
-c conda-forge
Cela accélère l’installation car conda connaît déjà les versions recherchées.
2.5 Commandes essentielles
Inspecter vos environnements
Ces commandes vous permettent de savoir où vous êtes et ce que vous avez installé :
| Commande | Résultat | Quand l’utiliser |
|---|---|---|
conda env list |
Liste tous vos environnements | Voir quels projets existent |
conda list |
Librairies dans l’environnement actif | Vérifier versions installées |
conda list gdal |
Info sur une librairie spécifique | Vérifier si GDAL est installé et sa version |
Exemple pratique :
conda env list
conda list
conda list gdal
Nettoyer l’espace disque
Problème courant : Le cache Conda grandit rapidement (+ 5 GB après quelques mois d’utilisation). Les environnements de test s’accumulent et remplissent votre disque.
| Commande | Effet | Quand l’utiliser |
|---|---|---|
conda clean --all --dry-run |
Voir ce qui sera supprimé (sans supprimer) | Avant de nettoyer |
conda clean --all |
Supprimer cache et librairies inutilisées | Une fois par mois |
conda remove -n old-env --all |
Supprimer complètement un environnement | Projet terminé |
Exemple pratique :
conda clean --all --dry-run
conda clean --all
conda remove -n test-env --all
Exporter pour reproductibilité
Règle d’or : Toujours exporter environment.yml avant de committer sur Git.
| Commande | Résultat | Avantage |
|---|---|---|
conda env export > environment.yml |
Fichier avec toutes les dépendances (100+ lignes) | Reproductibilité exacte |
conda env export --from-history > environment.yml |
Fichier avec seulement librairies explicitement installées (10-15 lignes) | Lisible et maintenable |
Recommandation : Utilisez --from-history pour un fichier propre et lisible.
Exemple pratique :
conda activate geo-env
conda env export --from-history > environment.yml
git add environment.yml
git commit -m "Ajouter environment.yml pour reproductibilité"
Erreurs courantes à éviter
| Mauvaise pratique | Bonne pratique |
|---|---|
conda install geopandas dans (base) |
Créer un nouvel environnement dédié |
Supprimer le dossier miniforge3/ manuellement |
Utiliser conda remove -n env --all |
Mélanger pip install et conda install sans ordre |
Toujours conda en premier, pip ensuite si nécessaire |
Pourquoi ne jamais toucher à (base) ? Si vous cassez l’environnement de base, vous cassez Conda lui-même et devrez réinstaller Miniforge.
3.1 Interface VSCode
Télécharger et installer VSCode
- Visiter code.visualstudio.com
- Télécharger pour votre système
- Installer avec paramètres par défaut
Ouvrir un dossier projet
- Ouvrir VSCode
- File → Open Folder
- Sélectionner votre dossier de projet
- Cliquer Select Folder
Les panneaux principaux
Figure 3 : Interface VSCode en action - À gauche : Explorer avec arborescence de fichiers du projet. Centre : Éditeur principal affichant du code R. Bas : Panel avec onglets (Problems, Output, Terminal) - notez l’environnement Conda (base) actif dans le terminal. Haut : Menu et barre d’onglets pour naviguer entre fichiers ouverts.
Zones principales :
- Sidebar gauche : Explorer, Search, Source Control, Extensions
- Éditeur central : Zone de code avec coloration syntaxique
- Panel inférieur : Terminal, Problems, Output, Debug Console
- Status Bar (bas) : Informations sur le fichier, Git, et interpréteur Python
Les sections du Sidebar
Cliquer l’icône pour naviguer :
- Explorateur (Ctrl+B) : Arborescence fichiers
- Search (Ctrl+Shift+F) : Chercher dans tous fichiers
- Source Control (Ctrl+Shift+G) : Git integration
- Run and Debug (Ctrl+Shift+D) : Debugger Python
- Extensions (Ctrl+Shift+X) : Installer packages VSCode
3.2 Extensions VSCode
Top 5 extensions pour géomatique
| Extension | Utilité | Installer |
|---|---|---|
| Python | Support complet Python (Microsoft) | Obligatoire |
| Jupyter | Notebooks interactifs | Fortement recommandé |
| Pylance | Autocomplétion avancée | Recommandé |
| GitLens | Git visualization améliorée | Recommandé |
| Data Wrangler | Exploration visuelle pandas | Recommandé |
Installer une extension
- Ouvrir Extensions (Ctrl+Shift+X)
- Chercher “Python” (par Microsoft)
- Cliquer Install
- Attendre installation et Reload
Configuration post-installation
Après avoir installé l’extension Python :
-
Ouvrir Command Palette (Ctrl+Shift+P)
-
Taper “Python: Select Interpreter”
-
Choisir votre
geo-env: VSCode affichera un interpréteur du typeC:\Users\YourName\miniforge3\envs\geo-env\python.exe(ou/Users/YourName/miniforge3/envs/geo-env/bin/pythonsur macOS/Linux).
Vérifier avec Python :
import geopandas
print("Succès !")
3.3 Terminal et Conda
Ouvrir le terminal intégré
Ctrl + ` (backtick)
ou Terminal → New Terminal
Vérifier que Conda est actif
conda --version
Activer votre environnement
conda activate geo-env
Vous verrez :
(geo-env) C:\Users\YourName\project >
Lancer Python interactif
python
>>> import geopandas as gpd
>>> import rasterio
>>> print("Prêt pour la géomatique.")
Prêt pour la géomatique.
Quitter avec exit() ou Ctrl+D.
Lancer un Jupyter Notebook
jupyter notebook
Ou dans VSCode directement :
- Créer fichier
analyse.ipynb - Cliquer Select Kernel
- Choisir
geo-env - Commencer à coder !
Validation rapide : Pour tester votre environnement, ouvrez le notebook 01a-validation-rapide.ipynb (2-3 minutes). Pour un exemple avancé avec données Sentinel-2 réelles, consultez 01b-exemple-sentinel2-avance.ipynb (10-15 minutes).
3.4 Git et GitHub
Pourquoi Git est indispensable pour la science des données
Vous avez terminé un projet de classification d’images satellites il y a trois mois. Aujourd’hui, votre directeur vous demande : “Pouvez-vous refaire cette analyse avec les données mises à jour de décembre ?”
Vous trouvez votre code, mais vous n’êtes plus certain :
- Quel était votre environment.yml exact ? (librairies et versions)
- Avez-vous modifié l’algorithme après la publication ? (quelle version final ?)
- Qui a fait quel changement au code ? (traçabilité)
- Pouvez-vous revenir à une version antérieure rapidement ?
Git résout tous ces problèmes. C’est un système de contrôle des versions qui enregistre chaque changement apporté à votre code, avec qui a fait le changement, quand, et pourquoi.
Git vs GitHub : Quelle différence ?
Git et GitHub sont deux outils distincts qui travaillent ensemble :
| Outil | Type | Rôle | Exemple |
|---|---|---|---|
| Git | Logiciel local | Système de contrôle de versions installé sur votre ordinateur | Enregistre l’historique de vos fichiers localement |
| GitHub | Plateforme web | Service cloud pour héberger et partager vos dépôts Git | Sauvegarde votre code en ligne et permet la collaboration |
Analogie simple :
- Git = votre journal personnel (vous écrivez localement)
- GitHub = votre blogue public (vous publiez en ligne pour que d’autres le lisent)
En pratique :
- Vous utilisez Git pour versionner votre code localement (
git commit) - Vous utilisez GitHub pour sauvegarder/partager votre code en ligne (
git push) - Vos collaborateurs utilisent GitHub pour télécharger votre code (
git clone)
Vous pouvez utiliser Git sans GitHub (versioning local seulement), mais GitHub nécessite Git pour fonctionner.
Au-delà de la traçabilité : collaboration et reproductibilité
Collaboration : Vous travaillez avec deux collègues sur le même projet. Sans Git :
- Vous envoyez
analyse_v1.pypar email - Collègue A le modifie →
analyse_v1_aaa.py - Collègue B le modifie aussi →
analyse_v1_bbb.py - Vous recevez deux versions différentes… comment les fusionner ?
Avec Git, vous travaillez sur la même branche (version) du code. Les changements se fusionnent automatiquement ou demandent révision (Pull Request).
Reproductibilité : Un chercheur externe lit votre publication et veut reproduire vos résultats. Git + environment.yml garantit qu’il peut recréer EXACTEMENT votre environnement et exécuter EXACTEMENT le code que vous aviez.
Installer Git
Avant d’utiliser Git, vous devez d’abord l’installer sur votre ordinateur.
Vérifier si Git est déjà installé :
Ouvrir un terminal et taper :
git --version
Résultat attendu :
- Si installé :
git version 2.x.x - Si pas installé :
'git' n'est pas reconnu en tant que commande...
Installation de Git (si nécessaire) :
- Visiter git-scm.com/downloads
- Télécharger l’installateur pour Windows
- Exécuter l’installateur avec les options par défaut
- Important : Lors de l’installation, cocher “Git Bash” et “Git from the command line”
- Redémarrer VSCode après l’installation
- Vérifier l’installation :
git --version
Note : Si vous avez installé GitHub Desktop, Git est déjà inclus automatiquement.
Initialiser Git dans votre projet
Dans le terminal VSCode (avec geo-env actif) :
git init
git config --global user.name "Votre Nom Complet"
git config --global user.email "votre.email@uqtr.ca"
Ces commandes créent un dossier .git caché qui track tous les changements.
Ajouter et committer vos fichiers
Via interface VSCode (recommandé pour débuter) :
- Ouvrir Source Control (Ctrl+Shift+G)
- VSCode affiche les fichiers modifiés (rouge = nouveau, bleu = modifié)
- Cliquer + à côté chaque fichier pour les “stage” (préparer pour commit)
- Entrer un message de commit explicite (ex: “Ajouter analyse NDVI avec calcul de statistiques”)
- Cliquer le bouton de commit pour créer le commit
Via terminal (plus contrôle) :
git status
git add .
git commit -m "Ajouter analyse NDVI avec calcul de statistiques"
git log --oneline
Messages de commit clairs : une bonne pratique
Un bon message de commit explique le POURQUOI, pas le quoi :
git commit -m "modif"
git commit -m "fix bug"
git commit -m "Implémenter calcul NDVI pour images Sentinel-2"
git commit -m "Corriger reprojection WGS84 (issue #12)"
git commit -m "Ajouter visualisation Folium pour résultats cartographiques"
Connecter votre repo local à GitHub (sauvegarde + collaboration)
Jusqu’à présent, votre repo existe seulement sur votre ordinateur. GitHub permet de :
- Sauvegarder sur le cloud (pas de perte si le disque dur crash)
- Partager avec collègues
- Collaborer via Pull Requests
Étape 1 : Créer repository sur GitHub
- Aller sur github.com/new
- Remplir :
- Repository name :
mon-projet-geo - Description : “Analyse d’images satellites Sentinel-2 pour cartographie de zones protégées”
- Visibility : Public (bon pour science reproductible) ou Private (pour données sensibles)
- Repository name :
- Ne pas cocher “Initialize with README” (vous en avez déjà un)
- Créer repository
Étape 2 : Connecter votre repo local à GitHub
GitHub vous affichera les commandes. Copiez-les dans VSCode terminal :
git remote add origin https://github.com/votrecompte/mon-projet-geo.git
git branch -M main
git push -u origin main
Votre code est maintenant sauvegardé et visible sur GitHub.
Séquence Git résumée
Code modifié → git add . → git commit -m "message" → git push
↑
(envoie sur GitHub)
3.5 Démarche complète
Pourquoi cette séquence de trois outils ?
Jusqu’à présent, nous avons exploré trois briques fondamentales en isolation :
- Conda : isoler l’environnement et geler les versions
- VSCode : écrire et tester le code
- Git/GitHub : tracer les changements et collaborer
Or, ces trois outils fonctionnent mieux ensemble qu’en silos. Voici pourquoi :
Imaginez que vous terminez une analyse d’indice de végétation (NDVI) en mai 2025 en utilisant :
environment.ymlavec GDAL 3.8.0, Rasterio 1.3.5, NumPy 1.26.0- Script Python
analyse_ndvi.pyque vous avez itéré 15 fois - Un collègue qui clone votre repo en octobre 2025
Sans Git + environment.yml : Votre collègue clone le code, mais :
- Quel était l’environnement exact ? (quelles versions ?)
- Qui a modifié quoi et pourquoi ? (git log montre un historique vide)
- Le code fonctionne différemment en octobre vs mai (GDAL a changé)
Avec Git + environment.yml + VSCode : Votre collègue :
- Voit
environment.ymlet reproduit exactement votre environnement (conda env create -f environment.yml) - Voit
git loget understand chaque étape : “Sept 12: Corriger extraction bandes → Oct 5: Ajouter masquage nuages” - Le code fonctionne à l’identique en octobre car les librairies sont gelées
- VSCode détecte automatiquement l’environnement correct grâce aux configuration Conda intégrées
Cet exemple montre un triple bénéfice qui émerge seulement en combinaison.
Scénario réaliste : de zéro à livrable publiable
Vous démarrez un nouveau projet de cartographie NDVI fin septembre 2025 sur une région test. Voici la démarche complète de ce projet (estimé 45 minutes).
Étape 1 : Préparer l’environnement isolé (Conda)
Vous créez un dossier projet avec structure claire :
mkdir D:\Projets\ndvi-region-test
cd D:\Projets\ndvi-region-test
mkdir donnees scripts resultats
Créer l’environnement Conda spécifique au projet :
conda create -n ndvi-project python=3.11 -y
conda activate ndvi-project
Vous devriez voir (ndvi-project) au début de votre invite.
Installer les librairies géospatiales depuis conda-forge :
conda install -c conda-forge geopandas rasterio gdal numpy pandas scipy jupyter -y
Rappel : Avec Miniforge, le -c conda-forge est optionnel (voir section 2.4). Nous le gardons ici pour clarté.
Point de validation : Toutes les librairies s’installent sans erreur. Vous voyez Preparing transaction: done.
Geler l’environnement pour reproductibilité :
conda env export > environment.yml
Ceci crée un fichier environment.yml qui capture exactement les versions. Ce fichier sera sauvegardé sur GitHub.
Étape 2 : Ouvrir le projet dans VSCode
Depuis le terminal activé, lancez VSCode :
code .
VSCode ouvre et scanne le dossier. Configurez l’interprète Python :
- Ctrl+Shift+P →
Python: Select Interpreter - Choisir
./miniforge3/envs/ndvi-project/python.exe(la version Conda que vous venez de créer)
Point de validation : En bas à droite, vous voyez 3.11.x ('ndvi-project') au lieu de Python global.
Ouvrir le terminal intégré VSCode : Ctrl+`
Vous voyez :
(ndvi-project) D:\Projets\ndvi-region-test>
Cette activation automatique du terminal Conda montre que VSCode détecte l’environnement.
Étape 3 : Créer et tester le script d’analyse (VSCode)
Créer un fichier scripts/analyse_ndvi.py dans l’explorateur VSCode.
Copier ce code d’analyse complet :
"""
Analyse NDVI pour région test
Charge un raster NDVI et calcule statistiques + couverture
"""
import numpy as np
import rasterio
from pathlib import Path
from rasterio.transform import from_bounds
data_dir = Path("donnees")
output_dir = Path("resultats")
data_dir.mkdir(exist_ok=True)
output_dir.mkdir(exist_ok=True)
ndvi_file = data_dir / "ndvi_test.tif"
if not ndvi_file.exists():
print("Fichier ndvi_test.tif non trouvé. Créons un raster de démo...")
# Données NDVI fictives
ndvi_data = np.random.uniform(-0.3, 0.8, size=(512, 512)).astype(np.float32)
# Métadonnées exemple (région Montréal)
bounds = (-73.5, 45.0, -72.5, 46.0)
transform = from_bounds(*bounds, 512, 512)
# Écrire raster
with rasterio.open(
ndvi_file, 'w',
driver='GTiff',
height=512, width=512,
count=1, dtype=ndvi_data.dtype,
crs='EPSG:4326',
transform=transform
) as dst:
dst.write(ndvi_data, 1)
print(f"Raster créé: {ndvi_file}")
print("\n=== ANALYSE NDVI RÉGION TEST ===")
print("=" * 50)
with rasterio.open(ndvi_file) as src:
ndvi = src.read(1)
profile = src.profile
# Statistiques de base
print(f"\nSTATISTIQUES")
print(f" Dimensions: {ndvi.shape[0]} × {ndvi.shape[1]} pixels")
print(f" Min NDVI: {ndvi.min():.4f}")
print(f" Max NDVI: {ndvi.max():.4f}")
print(f" Moyenne NDVI: {ndvi.mean():.4f}")
print(f" Écart-type: {ndvi.std():.4f}")
# Classification couverture
print(f"\nCLASSIFICATION COUVERTURE")
eau = np.sum(ndvi < -0.1)
sol = np.sum((ndvi >= -0.1) & (ndvi < 0.2))
vegetation = np.sum(ndvi >= 0.2)
total = ndvi.size
print(f" Eau: {eau:,} pixels ({100*eau/total:.1f}%)")
print(f" Sol nu: {sol:,} pixels ({100*sol/total:.1f}%)")
print(f" Végétation: {vegetation:,} pixels ({100*vegetation/total:.1f}%)")
# Sauvegarder rapport
report_file = output_dir / "rapport_ndvi.txt"
with open(report_file, 'w') as f:
f.write("RAPPORT ANALYSE NDVI - RÉGION TEST\n")
f.write("=" * 50 + "\n\n")
f.write(f"Date analyse: 2025-09-30\n")
f.write(f"Fichier source: {ndvi_file}\n\n")
f.write(f"STATISTIQUES\n")
f.write(f" Min: {ndvi.min():.4f}\n")
f.write(f" Max: {ndvi.max():.4f}\n")
f.write(f" Moyenne: {ndvi.mean():.4f}\n\n")
f.write(f"COUVERTURE\n")
f.write(f" Eau: {eau:,} ({100*eau/total:.1f}%)\n")
f.write(f" Sol: {sol:,} ({100*sol/total:.1f}%)\n")
f.write(f" Végétation: {vegetation:,} ({100*vegetation/total:.1f}%)\n")
print(f"\nRapport sauvegardé: {report_file}")
print("\nAnalyse terminée !")
Exécuter le script : F5 ou Terminal python scripts/analyse_ndvi.py
Point de validation : Vous voyez en output :
=== ANALYSE NDVI RÉGION TEST ===
==================================================
STATISTIQUES
Dimensions: 512 × 512 pixels
Min NDVI: -0.2987
Max NDVI: 0.7945
Moyenne NDVI: 0.2345
Écart-type: 0.3821
CLASSIFICATION COUVERTURE
Eau: 45,123 pixels (17.2%)
Sol nu: 89,456 pixels (34.1%)
Végétation: 156,789 pixels (59.7%)
Rapport sauvegardé: resultats/rapport_ndvi.txt
Analyse terminée !
Cet output montre que :
- Rasterio fonctionne (lit/écrit GeoTIFF)
- NumPy fonctionne (calculs vectorisés)
- Pathlib fonctionne (gestion chemins cross-platform)
- Votre environnement Conda est correct
Étape 4 : Explorer et visualiser (VSCode + Jupyter)
Créer un notebook exploration.ipynb dans le dossier racine (VSCode détecte l’extension .ipynb et active Jupyter).
Cellule 1 (import et chargement) :
import numpy as np
import matplotlib.pyplot as plt
import rasterio
from pathlib import Path
ndvi_file = Path("donnees/ndvi_test.tif")
with rasterio.open(ndvi_file) as src:
ndvi = src.read(1)
bounds = src.bounds
print(f"NDVI shape: {ndvi.shape}")
print(f"Valeurs: [{ndvi.min():.2f}, {ndvi.max():.2f}]")
Cellule 2 (visualiser distribution) :
plt.figure(figsize=(10, 5))
plt.hist(ndvi.flatten(), bins=50, edgecolor='black', color='steelblue')
plt.xlabel("Valeur NDVI")
plt.ylabel("Fréquence (pixels)")
plt.title("Distribution NDVI - Région test")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
Cellule 3 (visualiser carte) :
fig, ax = plt.subplots(figsize=(10, 8))
im = ax.imshow(ndvi, cmap='RdYlGn', vmin=-0.3, vmax=0.8, extent=[bounds.left, bounds.right, bounds.bottom, bounds.top])
cbar = plt.colorbar(im, ax=ax, label='NDVI')
ax.set_title("Carte NDVI - Région test (Mercator)", fontsize=14)
ax.set_xlabel("Longitude")
ax.set_ylabel("Latitude")
plt.tight_layout()
plt.show()
Exécuter chaque cellule avec Shift+Enter.
Point de validation :
- Cellule 1 affiche dimensions (512, 512) et gamme NDVI
- Cellule 2 montre histogramme avec distribution normale
- Cellule 3 montre carte colorée avec dégradés rouge (eau/sol) → vert (végétation)
Le notebook démontre que l’exploration interactive fonctionne. Vous avez maintenant :
- Script reproductible (
analyse_ndvi.py) - Exploration interactive (
exploration.ipynb) - Rapport sauvegardé (
resultats/rapport_ndvi.txt)
Étape 5 : Tracer les changements (Git)
À ce stade, vous avez des fichiers à sauvegarder et tracer.
Initialiser Git une fois par projet :
git init
git config user.name "Votre Nom"
git config user.email "votre.email@uqtr.ca"
Créer .gitignore pour exclure fichiers inutiles (créer à la racine) :
__pycache__/
*.pyc
.ipynb_checkpoints/
donnees/*.tif
donnees/*.shp
resultats/*.tif
.vscode/
.idea/
Ajouter tous les fichiers importants et committer :
git add scripts/ exploration.ipynb environment.yml .gitignore README.md
git commit -m "Implémenter analyse NDVI avec classification couverture
- Créer script analyse_ndvi.py pour calcul stats et couverture végétale
- Ajouter notebook d'exploration avec visualisations matplotlib
- Geler environment.yml pour reproductibilité (GDAL 3.8, Rasterio 1.3)
- Documenter structure projet dans README"
Point de validation : Vous voyez :
4 files changed, 287 insertions(+)
Vérifier l’historique :
git log --oneline
Vous devez voir votre commit :
a3f7d8e Implémenter analyse NDVI avec classification couverture
Étape 6 : Publier sur GitHub (Git + GitHub)
À ce point, votre projet local est tracé. Pour collaborer ou le rendre public :
- Créer repo sur GitHub
- Visiter https://github.com/new
- Nom :
ndvi-region-test - Description : “Analyse NDVI de la région test avec classification couverture (GDAL, Rasterio)”
- Visibilité : Public
- Créer repo
- Connecter repo local à GitHub
Copier les commandes que GitHub affiche. Dans VSCode terminal :
git branch -M main
git remote add origin https://github.com/VOTRE_COMPTE/ndvi-region-test.git
git push -u origin main
Point de validation :
- GitHub affiche votre repo avec tous les fichiers
- Vous voyez le commit et le message complet
environment.ymlest visible et lisiblescripts/analyse_ndvi.pycontient votre code avec numéros de ligne- Notebook
exploration.ipynbest affiché avec rendu des cellules
Résumé des trois couches en action
| Couche | Outil | Rôle | Artefact |
|---|---|---|---|
| Isolation | Conda | Geler versions exactes pour reproductibilité | environment.yml |
| Développement | VSCode + Jupyter | Écrire, tester, explorer interactivement | scripts/*.py, *.ipynb |
| Traçabilité | Git | Enregistrer qui/quand/pourquoi changements | git log → historique |
| Collaboration | GitHub | Rendre code accessible, partager, revue | Repo public avec branches |
L’intégration : Ces quatre éléments (environment.yml + VSCode + Git + GitHub) forment un système cohérent. Quand un collègue clone votre repo :
git clone https://github.com/VOTRE_COMPTE/ndvi-region-test.git
cd ndvi-region-test
conda env create -f environment.yml
conda activate ndvi-region-test
code .
En moins de 2 minutes, votre collègue a :
- Votre code exact
- Votre environnement exact
- L’historique exact des changements
- VSCode configuré correctement
Ceci est impossible avec seulement Conda, seulement VSCode, ou seulement Git isolément. C’est la combinaison qui crée la magie.
Exemple pratique complet : Pour suivre une pratique guidée de bout en bout (30 minutes), consultez 02-pratique-projet-complet.md.
4. Ressources
Fichiers ressources
- environment.yml - Librairies géospatiales pré-configurées
- settings.json - Configuration VSCode optimale
- extensions-recommandees.md - Extensions détaillées
Exercices pratiques
01-test-environnement.ipynb — Exercice de test de l’environnement
Télécharger 01-test-environnement.ipynb
02-importation-satellite.ipynb — Importation d’images satellitaires
Télécharger 02-importation-satellite.ipynb
Documentation officielle
Problèmes courants et solutions
| Problème | Cause | Solution |
|---|---|---|
ModuleNotFoundError: No module named 'geopandas' |
Mauvais environnement Python | Vérifier interprète VSCode → Python: Select Interpreter |
conda: command not found |
Conda pas dans PATH | Relancer le shell ou terminal |
| GDAL installation échoue | Dépendances manquantes | Utiliser conda-forge channel |
| VSCode ne trouve pas Jupyter | Extension non installée | Installer extension Jupyter officielle |
Points clés à retenir
- Conda isole chaque projet → pas de conflits de versions
- environment.yml rend projets reproductibles
- VSCode détecte automatiquement environnement Conda
- Git/GitHub permettent collaboration efficace
- Extensions VSCode augmentent productivité
Prochaines étapes
- Installer Miniforge
- Créer
geo-envavec GeoPandas - Configurer VSCode
- Faire premier commit Git
- Pousser sur GitHub
- Commencer votre projet géomatique !
Formation complétée !
Pour questions : consultez les ressources ou la documentation officielle.
Annexe A — Test de l’environnement
Durée estimée : 1-2 minutes Prérequis : Section 3.3 de la formation Objectif : Vérifier que les librairies géospatiales sont installées et fonctionnelles
Téléchargement des données
Ce notebook nécessite l’image Sentinel-2 de Saskatchewan-Athabasca.
Téléchargement automatique : La cellule suivante télécharge automatiquement les données depuis Google Drive (recommandé).
Téléchargement manuel : Cliquez ici et placez dans atelier/data/saskatchewan_athabasca_clip.tif
Cliquez sur Run All en haut du notebook, ou exécutez chaque cellule individuellement.
Téléchargement automatique des données depuis Google Drive
import os
import requests
from pathlib import Path
FILE_ID = "1ssjG8ZO4jP8U0bZ78jkDuotafv-Py3yH"
DATA_DIR = Path("../data")
FILE_PATH = DATA_DIR / "saskatchewan_athabasca_clip.tif"
DATA_DIR.mkdir(exist_ok=True)
if not FILE_PATH.exists():
print("Téléchargement de l'image Saskatchewan-Athabasca depuis Google Drive...")
url = f"https://drive.google.com/uc?export=download&id={FILE_ID}"
response = requests.get(url, allow_redirects=True)
response.raise_for_status()
with open(FILE_PATH, 'wb') as f:
f.write(response.content)
file_size_mb = FILE_PATH.stat().st_size / 1024 / 1024
print(f"Téléchargement terminé : {FILE_PATH}")
print(f" Taille : {file_size_mb:.1f} MB")
else:
print(f"Données déjà présentes : {FILE_PATH}")
Imports et versions
import os
import rasterio
import matplotlib.pyplot as plt
import numpy as np
print(f"rasterio: {rasterio.__version__}")
print(f"numpy: {np.__version__}")
print("\nLes librairies géospatiales sont installées")
Résultat attendu :
rasterio: 1.3.8
numpy: 1.24.3
Les librairies géospatiales sont installées
Lecture et visualisation
from pathlib import Path
image_path = Path("../data/saskatchewan_athabasca_clip.tif")
with rasterio.open(image_path) as src:
red = src.read(4) # Bande 4 - Rouge
green = src.read(3) # Bande 3 - Vert
blue = src.read(2) # Bande 2 - Bleu
nir = src.read(8) # Bande 8 - NIR
def normalize(band):
# détecter les Nodata
valid = band[~np.isnan(band)]
# calculer percentiles
p2, p98 = np.percentile(valid, (2, 98))
# normaliser et clipper
normalized = np.clip((band - p2) / (p98 - p2), 0, 1)
return normalized
red_norm = normalize(red)
green_norm = normalize(green)
blue_norm = normalize(blue)
brightness = 1.2 # > 1.0 = plus lumineux
gamma = 0.6 # < 1.0 = plus clair, > 1.0 = plus sombre
red_corrected = np.clip(np.power(red_norm * brightness, gamma), 0, 1)
green_corrected = np.clip(np.power(green_norm * brightness, gamma), 0, 1)
blue_corrected = np.clip(np.power(blue_norm * brightness, gamma), 0, 1)
rgb = np.dstack([red_corrected, green_corrected, blue_corrected])
plt.figure(figsize=(10, 8))
plt.imshow(rgb)
plt.title('Image satellite Sentinel-2 - Composition RGB')
plt.axis('off')
plt.tight_layout()
plt.show()
print("Validation réussie")
Résultat attendu :
- Une image couleur affichée (composition RGB de la région Saskatchewan-Athabasca)
- Message de confirmation :
Validation réussie
Distribution spectrale RGB + NIR
plt.figure(figsize=(10, 6))
plt.hist(red[~np.isnan(red)].flatten(), bins=200, alpha=0.6, color='red', label='Rouge (B4)', edgecolor='darkred')
plt.hist(green[~np.isnan(green)].flatten(), bins=200, alpha=0.6, color='green', label='Vert (B3)', edgecolor='darkgreen')
plt.hist(blue[~np.isnan(blue)].flatten(), bins=200, alpha=0.6, color='blue', label='Bleu (B2)', edgecolor='darkblue')
plt.hist(nir[~np.isnan(nir)].flatten(), bins=200, alpha=0.6, color='darkred', label='NIR (B8)', edgecolor='black')
plt.xlim(500, 6000)
plt.xlabel('Valeurs de réflectance')
plt.ylabel('Fréquence (pixels)')
plt.title('Distribution spectrale des bandes (RGB + NIR)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("Distribution spectrale affichée")
Résultat attendu :
- Un histogramme multicolore avec 4 courbes (Rouge, Vert, Bleu, NIR)
- Message :
Distribution spectrale affichée
Calcul et visualisation NDSI
with rasterio.open(image_path) as src:
swir = src.read(11) # Bande 11 - SWIR (infrarouge moyen)
green_norm = normalize(green)
swir_norm = normalize(swir)
denom = green_norm + swir_norm
ndsi = np.where(denom > 0.0001, (green_norm - swir_norm) / denom, np.nan)
plt.figure(figsize=(10, 8))
plt.imshow(ndsi, cmap='Blues', vmin=-0.5, vmax=1)
plt.colorbar(label='NDSI', shrink=0.6)
plt.title('Indice de neige NDSI')
plt.axis('off')
plt.tight_layout()
plt.show()
print(f"NDSI calculé - Moyenne: {np.nanmean(ndsi):.3f}")
Résultat attendu :
- Une carte NDSI affichée (gradient bleu montrant les zones enneigées)
- Message :
NDSI calculé - Moyenne: 0.XXX(valeur entre 0 et 1)
Annexe B — Importation satellite
Ce notebook illustre l’utilisation de données satellite réelles Sentinel-2 depuis le Microsoft Planetary Computer.
Source : Microsoft Planetary Computer (STAC API) Librairies : rasterio, pandas, matplotlib, seaborn, numpy, planetary-computer, pystac-client
Explorer le catalogue : https://planetarycomputer.microsoft.com/explore
Imports
import rasterio
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import planetary_computer
from pystac_client import Client
1. Connexion à Planetary Computer
Accès au catalogue STAC pour télécharger une image Sentinel-2.
catalog = Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=planetary_computer.sign_inplace
)
print("Connexion au Planetary Computer réussie")
item = catalog.get_collection("sentinel-2-l2a").get_item(
"S2B_MSIL2A_20250824T185919_R013_T11UMT_20250824T224700"
)
print(f"Item Sentinel-2 trouvé: {item.id}")
bands = {k: item.assets[k].href for k in ['B02', 'B03', 'B04', 'B08']}
print(f"4 bandes spectrales récupérées")
Output attendu :
Connexion au Planetary Computer réussie
Item Sentinel-2 trouvé: S2B_MSIL2A_20250824T185919_R013_T11UMT_20250824T224700
4 bandes spectrales récupérées
2. Chargement des bandes
Lecture des bandes spectrales (bleu, vert, rouge, NIR) avec masquage des valeurs invalides.
print("Chargement: peut prendre 30-60 secondes)")
with rasterio.open(bands['B02']) as src:
blue = src.read(1) # Lire la première (et unique) bande
transform = src.transform # Transformation affine (géoréférencement)
crs = src.crs # Système de coordonnées (ex: EPSG:32618 pour UTM Zone 18N)
nodata = src.nodata # Valeur représentant pixels invalides (nuages, ombres)
print(f"Bande bleue chargée (B02)")
with rasterio.open(bands['B03']) as src:
green = src.read(1)
print(f"Bande verte chargée (B03)")
with rasterio.open(bands['B04']) as src:
red = src.read(1)
print(f"Bande rouge chargée (B04)")
with rasterio.open(bands['B08']) as src:
nir = src.read(1)
print(f"Bande NIR chargée (B08)")
mask = (blue != nodata) & (green != nodata) & (red != nodata) & (nir != nodata)
blue_masked = np.where(mask, blue, np.nan)
green_masked = np.where(mask, green, np.nan)
red_masked = np.where(mask, red, np.nan)
nir_masked = np.where(mask, nir, np.nan)
print(f"\nToutes les bandes chargées et masquées")
print(f" Dimensions: {red.shape[0]} × {red.shape[1]} pixels")
print(f" Pixels valides: {np.sum(mask):,} / {mask.size:,} ({100*np.sum(mask)/mask.size:.1f}%)")
Output attendu :
Chargement: peut prendre 30-60 secondes)
Bande bleue chargée (B02)
Bande verte chargée (B03)
Bande rouge chargée (B04)
Bande NIR chargée (B08)
Toutes les bandes chargées et masquées
Dimensions: 10980 × 10980 pixels
Pixels valides: 118,331,336 / 120,560,400 (98.2%)
3. Statistiques avec la librarie Pandas
stats = pd.DataFrame({
'Bande': ['Bleu', 'Vert', 'Rouge', 'NIR'],
'Min': [np.nanmin(blue_masked), np.nanmin(green_masked), np.nanmin(red_masked), np.nanmin(nir_masked)],
'Max': [np.nanmax(blue_masked), np.nanmax(green_masked), np.nanmax(red_masked), np.nanmax(nir_masked)],
'Moyenne': [np.nanmean(blue_masked), np.nanmean(green_masked), np.nanmean(red_masked), np.nanmean(nir_masked)]
}).round(1)
stats
Output attendu :
| Bande | Min | Max | Moyenne |
|---|---|---|---|
| Bleu | 1.0 | 18144.0 | 1960.8 |
| Vert | 1.0 | 17472.0 | 2121.8 |
| Rouge | 203.0 | 17008.0 | 2080.1 |
| NIR | 1.0 | 16544.0 | 3114.8 |
4. Visualisation RGB
def norm(band, brightness=1.2, gamma=1.6):
p2, p98 = np.nanpercentile(band, (2, 98))
normalized = np.clip((band - p2) / (p98 - p2), 0, 1)
# Appliquer brightness
normalized = normalized * brightness
normalized = np.clip(normalized, 0, 1)
# Appliquer gamma correction
normalized = np.power(normalized, 1/gamma)
return normalized
rgb = np.dstack([
norm(red_masked, brightness=1.2, gamma=1.6),
norm(green_masked, brightness=1.2, gamma=1.6),
norm(blue_masked, brightness=1.2, gamma=1.6)
])
plt.figure(figsize=(10, 10))
plt.imshow(rgb)
plt.title('Sentinel-2 RGB')
plt.axis('off')
plt.show()
Résultat attendu :
- Une image couleur affichée (composition RGB de la région satellite)
- Les pixels lumineux correspondent aux zones sans nuages
6. Distribution des bandes
Histogramme lissé montrant la répartition des valeurs de réflectance pour chacune des bandes.
sns.set_style("whitegrid")
plt.figure(figsize=(12, 6))
sample_size = 50000
blue_valid = blue_masked[~np.isnan(blue_masked)]
green_valid = green_masked[~np.isnan(green_masked)]
red_valid = red_masked[~np.isnan(red_masked)]
nir_valid = nir_masked[~np.isnan(nir_masked)]
blue_sample = np.random.choice(blue_valid, size=min(sample_size, blue_valid.size), replace=False)
green_sample = np.random.choice(green_valid, size=min(sample_size, green_valid.size), replace=False)
red_sample = np.random.choice(red_valid, size=min(sample_size, red_valid.size), replace=False)
nir_sample = np.random.choice(nir_valid, size=min(sample_size, nir_valid.size), replace=False)
sns.kdeplot(blue_sample, color='blue', linewidth=2.5, bw_adjust=2, label='Bleu')
sns.kdeplot(green_sample, color='green', linewidth=2.5, bw_adjust=2, label='Vert')
sns.kdeplot(red_sample, color='red', linewidth=2.5, bw_adjust=2, label='Rouge')
sns.kdeplot(nir_sample, color='darkred', linewidth=2.5, bw_adjust=2, label='NIR')
plt.xlim(np.percentile(np.concatenate([blue_sample, green_sample, red_sample, nir_sample]), [1, 99]))
plt.title('Distribution des bandes spectrales')
plt.xlabel('Réflectance')
plt.ylabel('Densité')
plt.legend()
plt.tight_layout()
plt.show()
Résultat attendu :
- Un graphique KDE (noyau de densité) montrant 4 courbes lissées (Bleu, Vert, Rouge, NIR)
- Le NIR (courbe rouge foncée) montre généralement des valeurs plus élevées que les bandes visibles
Annexe C — Extensions VSCode recommandées
Guide détaillé des extensions essentielles pour développement en géomatique avec VSCode.
Priorité 1 : OBLIGATOIRE
Python (Microsoft)
Pourquoi : Support complet du langage Python, débogage, autocomplétion.
- ID :
ms-python.python - Installe aussi : Pylance (autocomplétion avancée)
- Post-installation :
- Ctrl+Shift+P → “Python: Select Interpreter”
- Choisir votre environnement Conda
Utilité quotidienne :
- Coloration syntaxique Python
- Débogage avec breakpoints
- Autocomplétion intelligente (via Pylance)
- Exécution de scripts
Priorité 2 : HAUTEMENT RECOMMANDÉ
Jupyter (Microsoft)
Pourquoi : Support natif des notebooks Jupyter dans VSCode.
- ID :
ms-toolsai.jupyter - Éléments fournis :
- Création/édition de
.ipynbdirectement - Exécution des cellules
- Visualisation des outputs (graphiques, tableaux)
- Kernel selection automatique
- Création/édition de
Utilité :
- Exploration interactive avec Jupyter
- Partage de notebooks exécutables
- Documentation avec mixes code/texte
Pylance (Microsoft)
Pourquoi : Autocomplétion ultra-rapide et intelligence de code avancée.
- ID :
ms-python.vscode-pylance - Fonctionnalités :
- Autocomplétion intelligente (IntelliSense)
- Type hints visualization
- Goto definition
- Refactoring automatique
Utilité :
- Évite les erreurs de typage
- Accélère la programmation
- Suggestion contextuelles intelligentes
GitLens (ErichBSchott)
Pourquoi : Visualisation Git améliorée directement dans l’éditeur.
- ID :
eamodio.gitlens - Fonctionnalités :
- Blame (qui a écrit cette ligne et quand)
- History (historique des changements)
- Diff between commits
- Repository explorer
Utilité :
- Comprendre l’historique du code
- Collaboration plus transparente
- Traçabilité rapide des modifications
Priorité 3 : RECOMMANDÉ
Data Wrangler (Microsoft)
Pourquoi : Exploration visuelle de dataframes Pandas.
- ID :
ms-toolsai.datawrangler - Fonctionnalités :
- Preview des données en tableau
- Filtrage et tri visuel
- Génération de code Python automatique
- Export en formats variés
Utilité pour géomatique :
- Inspectez rapidement les données vectorielles
- Explorez les attributs sans code
- Comprenez la structure des données avant analyse
Better Comments (Aaron Bond)
Pourquoi : Coloration améliorée des commentaires.
- ID :
aaron-bond.better-comments - Types de commentaires :
// !→ alerte (rouge)// ?→ question (bleu)// TODO→ à faire (orange)// *→ surligné (vert)
Utilité :
- Documentez votre code clairement
- Mettez en évidence les sections importantes
- Améliorez la lisibilité pour collaborateurs
Markdown All in One (Yu Zhang)
Pourquoi : Support complet Markdown avec preview en temps réel.
- ID :
yzhang.markdown-all-in-one - Fonctionnalités :
- Preview Markdown côte-à-côte
- Table of contents auto
- Formatting rapide
- Snippets courants
Utilité :
- Écrivez README.md clairement
- Documentez vos analyses
- Partagez rapports formatés
Utile pour géomatique spécifiquement
Rainbow CSV
Pourquoi : Coloration des colonnes CSV pour lisibilité.
- ID :
mechatroner.rainbow-csv - Utile pour : Inspecter données CSV/TSV avant import GeoPandas
GDAL (Tomáš Votruba)
Pourquoi : Syntax highlighting pour fichiers géospatiales.
- ID :
4source.gdal - Supporte : GeoJSON, WKT, OGR formats
SVG (Jock)
Pourquoi : Preview et édition de fichiers SVG.
- ID :
jock.svg - Utile pour : Visualiser et modifier cartographies générées
Productivité générale
Code Spell Checker
Pourquoi : Détection d’erreurs orthographe en français.
- ID :
streetsidesoftware.code-spell-checker - Langues : Ajouter “French” dans settings
TabNine (AutoComplete AI)
Pourquoi : Autocomplétion par AI (optionnel, Pylance souvent suffisant).
- ID :
TabNine.tabnine-vscode - Alternative gratuite : Pylance (recommandé)
Installation rapide
Copier-coller ces ID dans l’onglet Extensions (Ctrl+Shift+X) :
ms-python.python
ms-toolsai.jupyter
eamodio.gitlens
aaron-bond.better-comments
yzhang.markdown-all-in-one
Ou via terminal :
code --install-extension ms-python.python
code --install-extension ms-toolsai.jupyter
code --install-extension eamodio.gitlens
code --install-extension aaron-bond.better-comments
code --install-extension yzhang.markdown-all-in-one
Configuration recommandée dans settings.json
{
"python.linting.enabled": true,
"python.linting.pylintEnabled": true,
"python.formatting.provider": "black",
"jupyter.kernels.filter": [],
"[markdown]": {
"editor.wordWrap": "on",
"editor.defaultFormatter": "esbenp.prettier-vscode"
},
"gitlens.hovers.currentLine.enabled": true,
"gitlens.codeLens.enabled": true
}
Annexe D — Configuration VSCode
Fichier de configuration VSCode optimisé pour la géomatique et la science des données.
Installation
- Dans votre projet, créer le dossier
.vscode/à la racine - Copier le contenu ci-dessous dans
.vscode/settings.json - Relancer VSCode
Contenu du fichier
{
// === PYTHON ===
"python.defaultInterpreterPath": "${workspaceFolder}/env/Scripts/python.exe",
"python.linting.enabled": true,
"python.linting.pylintEnabled": false,
"python.linting.flake8Enabled": true,
"python.linting.flake8Args": ["--max-line-length=120"],
"python.formatting.provider": "black",
"python.formatting.blackArgs": ["--line-length=120"],
"[python]": {
"editor.formatOnSave": true,
"editor.codeActionsOnSave": {
"source.organizeImports": "explicit"
},
"editor.defaultFormatter": "ms-python.python"
},
// === JUPYTER NOTEBOOKS ===
"jupyter.notebookFileRoot": "${workspaceFolder}",
"notebook.cellToolbarLocation": "right",
"[jupyter]": {
"editor.defaultFormatter": "ms-python.python"
},
// === EDITOR ===
"editor.fontSize": 12,
"editor.fontFamily": "'IBM Plex Mono', 'Courier New', monospace",
"editor.lineHeight": 1.6,
"editor.rulers": [80, 120],
"editor.wordWrap": "on",
"editor.formatOnSave": true,
"editor.insertSpaces": true,
"editor.tabSize": 4,
"editor.trimAutoWhitespace": true,
// === APPEARANCE ===
"workbench.colorTheme": "One Dark Pro",
"workbench.iconTheme": "vs-nomo-dark",
"editor.minimap.enabled": true,
"editor.renderWhitespace": "selection",
// === FILE EXPLORER ===
"files.exclude": {
"**/__pycache__": true,
"**/*.pyc": true,
"**/.pytest_cache": true,
"**/.ipynb_checkpoints": true,
"**/.env": true
},
"files.watcherExclude": {
"**/.git/objects/**": true,
"**/.git/subtree-cache/**": true,
"**/node_modules/*/**": true,
"**/.pytest_cache/**": true
},
// === GIT ===
"git.enabled": true,
"git.ignoreLimitWarning": true,
"github.copilot.enable": {
"*": true,
"markdown": true,
"plaintext": false
},
// === TERMINAL ===
"terminal.integrated.defaultProfile.windows": "Command Prompt",
"terminal.integrated.profiles.windows": {
"PowerShell": {
"source": "PowerShell",
"icon": "terminal-powershell"
},
"Command Prompt": {
"path": ["${env:windir}\\Sysnative\\cmd.exe", "${env:windir}\\System32\\cmd.exe"],
"args": [],
"icon": "terminal-cmd"
}
},
"terminal.integrated.fontSize": 12,
"terminal.integrated.lineHeight": 1.4,
// === EXTENSIONS ===
"extensions.ignoreRecommendations": false,
// === SEARCH ===
"search.exclude": {
"**/.git": true,
"**/node_modules": true,
"**/__pycache__": true,
"**/*.egg-info": true
},
// === TELEMETRY (optionnel) ===
"telemetry.telemetryLevel": "off"
}
Téléchargement direct
Sections principales
Python
- Configuration de l’interpréteur par défaut
- Activation du linting avec flake8
- Formatage automatique avec Black (120 caractères)
- Organisation automatique des imports
Jupyter Notebooks
- Racine des notebooks au niveau du projet
- Barre d’outils des cellules à droite
Éditeur
- Police IBM Plex Mono
- Règles visuelles à 80 et 120 caractères
- Retour à la ligne automatique
- Formatage à la sauvegarde
Terminal
- Terminal par défaut : Command Prompt (compatible Conda)
- Configuration PowerShell disponible
Fichiers exclus
- Cache Python (
__pycache__,.pyc) - Checkpoints Jupyter
- Fichiers Git volumineux