Initiation à l’apprentissage automatique (Machine Learning)
Charles Martin
Mai 2019
- Introduction
- L’entraînement du modèle
- Chercher des visages dans une nouvelle page
- Problèmes et solutions
Introduction
Packages et fonctions nécessaires
library(tidyverse) # data manipulation
library(magick) # image manipulation
library(e1071) # svm model
library(OpenImageR) # HOG
source("Algorithmes.R") # Non-max suppression + bug HOG
Banque de visages
Il n’y a pas de secret, il faut observer l’image et noter les coordonnées de chaque visage. J’ai utilisé ImageJ pour accélérer le processus.
Voici un aperçu du fichier :
coords <- read_tsv(
"images/page1/full.txt",
col_names = c("X","Y")
)
head(coords)
# A tibble: 6 x 2
X Y
<dbl> <dbl>
1 476. 93.7
2 511. 342
3 608. 524.
4 541 553.
5 521 570.
6 486 566
J’ai eu la patience de noter 90 visages.
Par la suite, avec le package magick, nous allons créer une vignette pour chacune de ces images :
full <- image_read("images/page1/full.jpg")
thumb_size <- 16
for (i in 1:nrow(coords)) {
full %>%
image_crop(
geometry_area(
thumb_size,
thumb_size,
coords[[i,"X"]] - thumb_size/2, # Je sais que j'ai cliqué au milieu du visage...
coords[[i,"Y"]] - thumb_size/2
)
) %>%
image_write(paste0("images/page1/faces/",i,".jpg"))
}
Banque de non-visages
On va simplement piger aléatoirement un peu partout dans l’image…
set.seed(61523)
for (i in 1:600) {
random_x <- sample(
1:(image_info(full)$width - thumb_size),
1
)
random_y <- sample(
1:(image_info(full)$height - thumb_size),
1
)
full %>%
image_crop(
geometry_area(
thumb_size,
thumb_size,
random_x,
random_y
)
) %>%
image_write(paste0("images/page1/nonfaces/",i,".jpg"))
}
Comment traduire nos images pour l’algorithme d’apprentissage?
DIAPOS HOG
Extraire les caractéristiques des visages
files <- dir("images/page1/faces", full.names = TRUE)
faces <- HOG_apply2(files)
Extraire les caractéristiques des non-visages
files <- dir("images/page1/nonfaces", full.names = TRUE)
nonfaces <- HOG_apply2(files)
Préparation du jeu de données complet
X <- rbind(
faces,
nonfaces
)
Y <- as_factor(
rep(c("face","nonface"),
c(nrow(faces),nrow(nonfaces))
)
)
Segmentation du jeu de données
75% des données pour l’ajustement des hyperparamètres par validation croisée et 25 % pour le test du modèle final
set.seed(3978)
sample <- sample.int(
n = nrow(X),
size = floor(.75*nrow(X))
)
X_train <- X[sample, ]
X_test <- X[-sample, ]
Y_train <- Y[sample]
Y_test <- Y[-sample]
L’entraînement du modèle
Ajuster les hyperparamètres du SVM par validation croisée
set.seed(876)
tuned_params <- tune.svm(
# Envoyer les données
x = X_train,
y = Y_train,
# Valeurs possibles pour la validation croisée
gamma = c(0.0001,0.001,0.01),
cost = c(1,10,100),
tunecontrol = tune.control(cross = 4)
)
tuned_params
Parameter tuning of 'svm':
- sampling method: 4-fold cross validation
- best parameters:
gamma cost
0.001 10
- best performance: 0.07543232
Entraîner le modèle avec les hyperparamètres optimisés
trained_model <- svm(
x = X_train,
y = Y_train,
gamma = tuned_params$best.parameters$gamma,
cost = tuned_params$best.parameters$cost,
probability = TRUE
)
Vérifier la performance du modèle
pred <- predict(trained_model, X_test)
res <- table(pred, Y_test)
res
Y_test
pred face nonface
face 14 1
nonface 11 147
Il existe plusieurs façons de mesurer la performance du modèle
Accuracy : (TP + TN) / Total
Proportion de classifications correctes.
L’équivalent du R2, la performance totale du modèle.
Peu être problématique si le phénomène recherché est rare.
Precision : TP / (TP + FP)
Proportion des détections qui en sont des vraies.
À surveiller si les faux positifs sont ont une importance
Recall : TP / (TP + FN)
Un peu comme la probabilité de détection de notre algorithme.
À surveiller si on ne veut manquer aucun cas.
# Accuracy
sum(diag(res)) / sum(res)
[1] 0.9306358
# Precision
res[1,1] / (res[1,1] + res[1,2])
[1] 0.9333333
# Recall
res[1,1] / (res[1,1] + res[2,1])
[1] 0.56
Chercher des visages dans une nouvelle page
search_area <- image_read("images/page2/search_area.jpg")
Il faut d’abord déterminer avec quelle précision nous allons explorer l’image. Ici, j’ai choisi de sauter un pixel sur deux.
seq_x <- seq(
from = 1,
to = image_info(search_area)$width - thumb_size,
by = 2
)
seq_y <- seq(
from = 1,
to = image_info(search_area)$height - thumb_size,
by = 2
)
Lancer la recherche comme tel :
# Tableau de résultats
face_coords <- tibble(
x = NA,
y = NA,
probability = NA
)
# Pour chacune des coordonnées à explorer
for (x in seq_x) {
for (y in seq_y) {
# Aller chercher une section de l'image
thumb <- image_crop(
search_area,
geometry_area(
thumb_size,
thumb_size,
x,
y)
)
# Calculer ses caractéristiques
h <- HOG(
as.integer(image_data(thumb))/255,
# Il faut convertir les valeurs entre 0 et 1
# (l'autre fonction le faisait pour nous sans nous en parler)
cells = 8,
orientations = 8
)
# Envoyer les caractéristiques au SVM et
# voir si il croit que c'est un visage ou non
p <- predict(trained_model,t(h), probability = TRUE)
if (p == "face") {
face_coords <- face_coords %>%
add_row(
x = x,
y = y,
probability = attr(p,"probabilities")[2]
)
}
}
}
Visualiser le résultat
image_ggplot(search_area) +
geom_rect(
data = face_coords,
aes(
xmin = x,
xmax = x + thumb_size,
ymin = y,
ymax = y + thumb_size
),
fill = NA,
color = "red",
size = 2
)
Warning: Removed 1 rows containing missing values (geom_rect).
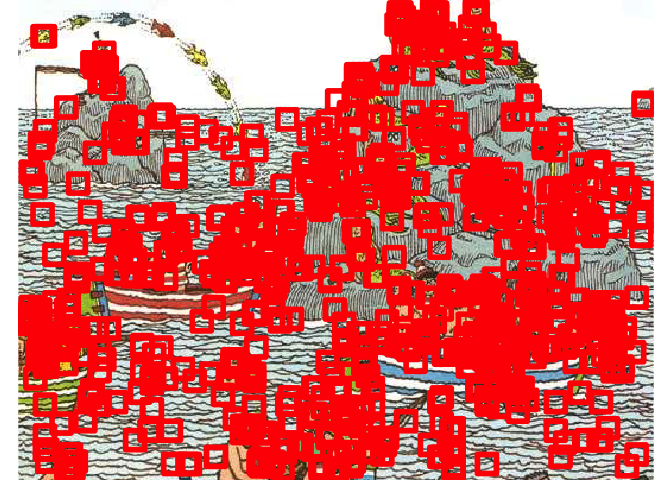
On a plusieurs problèmes à régler…
Problèmes et solutions
Éliminer les détections multiples
Puisque notre algorithme est robuste, il détecte le même visage plusieurs fois, à quelques pixels de décalage…
filtered_faces <- non_max_suppression(face_coords)
image_ggplot(search_area) +
geom_rect(
data = filtered_faces,
aes(
xmin = x,
xmax = x + thumb_size,
ymin = y,
ymax = y + thumb_size
),
fill = NA,
color = "red",
size = 2
)
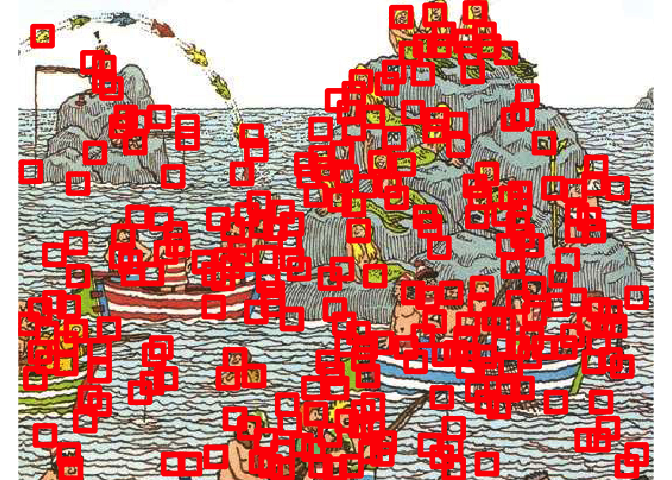
Surplus de faux positifs dans la nouvelle image
Mais clairement on détecte beaucoup de choses qui ne sont pas des visages. Les algorithmes ont besoin de beaucoup plus d’exemples de faux-positifs que nous. Entre autres, notre SVM semble vraiment embêté par les vagues, qui n’étaient pas présentes dans la première image.
Une façon d’améliorer ce problème est de conserver tous les faux positifs, et les remettre dans l’algorithme…
Différences de taille
Pour le moment notre algorithme ne cherche qu’à une échelle. Dans la vraie vie, il faudrait probablement chercher dans l’image à différentes échelles
Vitesse de détection
Malgré la taille modérée de notre image, le temps de recherche est relativement élevé. Cependant, cette tâche peut être paralélisée facilement en segmentant l’image et en lançant chacune des sections dans un processus différent.